-
핸즈온 머신러닝[2] 머신러닝 프로젝트 처음부터 끝까지(1)핸즈온머신러닝 2022. 4. 24. 18:57
https://www.youtube.com/watch?v=KMa5z3amwv4&list=PLJN246lAkhQjX3LOdLVnfdFaCbGouEBeb&index=7
캘리포니아 주택 가격 예측
- 인구, 중간 소득 등의 특성을 사용하여 중간 주택 가격 예측
- 다중 회귀: 여러개의 특성
- 단변량 회귀: 하나의 수치를 예측 (반대: 다변량 회귀)
- 회귀의 성능 측정: 평균 제곱근 오차(RMSE), 평균 절대 오차(MAE)
# 파이썬 ≥3.5 필수 import sys assert sys.version_info >= (3, 5) # 사이킷런 ≥0.20 필수 import sklearn assert sklearn.__version__ >= "0.20" # 공통 모듈 임포트 import numpy as np import os# 깔금한 그래프 출력을 위해 %matplotlib inline import matplotlib as mpl import matplotlib.pyplot as plt mpl.rc('axes', labelsize=14) mpl.rc('xtick', labelsize=12) mpl.rc('ytick', labelsize=12)# 그림을 저장할 위치 PROJECT_ROOT_DIR = "." CHAPTER_ID = "end_to_end_project" IMAGES_PATH = os.path.join(PROJECT_ROOT_DIR, "images", CHAPTER_ID) os.makedirs(IMAGES_PATH, exist_ok=True) def save_fig(fig_id, tight_layout=True, fig_extension="png", resolution=300): path = os.path.join(IMAGES_PATH, fig_id + "." + fig_extension) print("그림 저장:", fig_id) if tight_layout: plt.tight_layout() plt.savefig(path, format=fig_extension, dpi=resolution)import os import tarfile import urllib.request DOWNLOAD_ROOT = "https://raw.githubusercontent.com/rickiepark/handson-ml2/master/" HOUSING_PATH = os.path.join("datasets", "housing") HOUSING_URL = DOWNLOAD_ROOT + "datasets/housing/housing.tgz" def fetch_housing_data(housing_url=HOUSING_URL, housing_path=HOUSING_PATH): if not os.path.isdir(housing_path): os.makedirs(housing_path) tgz_path = os.path.join(housing_path, "housing.tgz") urllib.request.urlretrieve(housing_url, tgz_path) housing_tgz = tarfile.open(tgz_path) housing_tgz.extractall(path=housing_path) housing_tgz.close()fetch_housing_data()
실행결과 import pandas as pd def load_housing_data(housing_path=HOUSING_PATH): csv_path = os.path.join(housing_path, "housing.csv") return pd.read_csv(csv_path)csv 파일을 가져온다.
Data frame: 판다스에서 제공하는 다차원 배열 객체
housing = load_housing_data() housing.head()head 함수: 처음 다섯개 행을 잘라서 보여줌

실행결과 housing.info()info 함수: 데이터에 대한 간략한 설명데
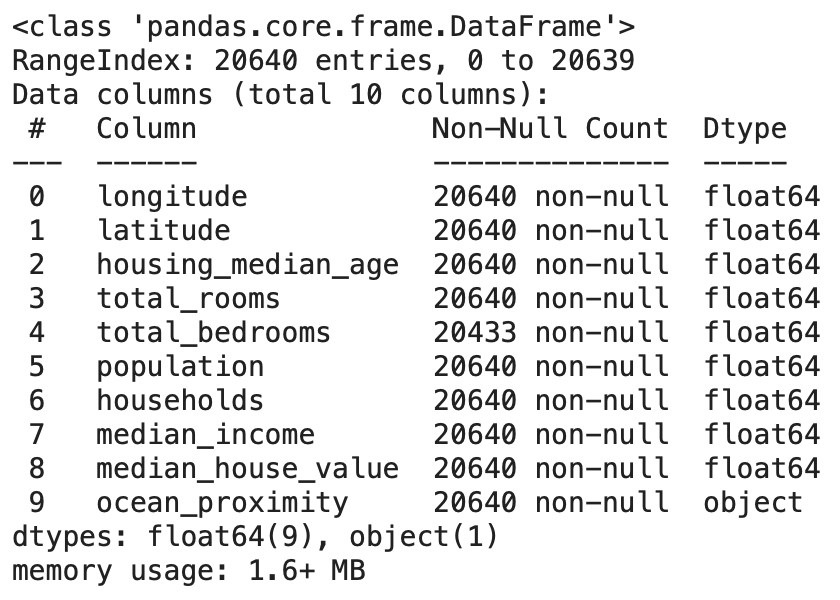
실행결과 ocean_proximity는 string으로 적혀있어서 Dtype이 object인것을 알 수 있음
housing["ocean_proximity"].value_counts()
실행결과 housing.describe()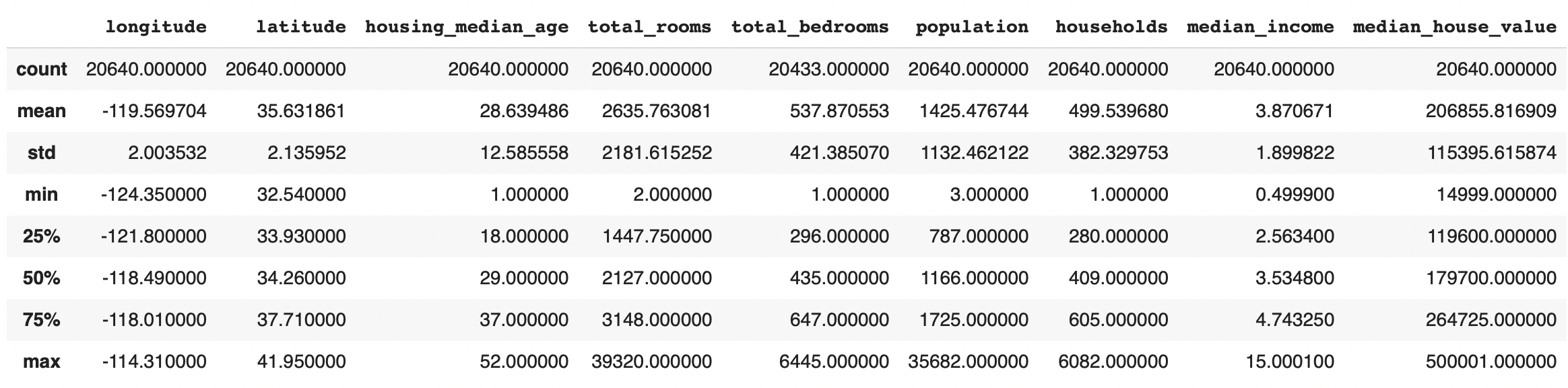
describe 함수: 각 특성의 열의 수치값을 요약해서 보여줌
%matplotlib inline import matplotlib.pyplot as plt housing.hist(bins=50, figsize=(20,15)) save_fig("attribute_histogram_plots") plt.show()bins: 구간

실행결과 테스트 세트 만들기
# 노트북의 실행 결과가 동일하도록 np.random.seed(42)import numpy as np # 예시로 만든 것입니다. 실전에서는 사이킷런의 train_test_split()를 사용하세요. def split_train_test(data, test_ratio): shuffled_indices = np.random.permutation(len(data)) test_set_size = int(len(data) * test_ratio) test_indices = shuffled_indices[:test_set_size] train_indices = shuffled_indices[test_set_size:] return data.iloc[train_indices], data.iloc[test_indices]permutation 함수: 배열을 입력하면 배열을 섞어주며 정수를 입력하면 0~정수 값을 섞어서 리턴해줌
train 데이터와 test 데이터를 분리
train_set, test_set = split_train_test(housing, 0.2) len(train_set)실행결과: 16512 (train set의 개수)
len(test_set)실행결과: 4128 (test set의 개수)
from zlib import crc32 def test_set_check(identifier, test_ratio): return crc32(np.int64(identifier)) & 0xffffffff < test_ratio * 2**32 def split_train_test_by_id(data, test_ratio, id_column): ids = data[id_column] in_test_set = ids.apply(lambda id_: test_set_check(id_, test_ratio)) return data.loc[~in_test_set], data.loc[in_test_set]데이터가 추가되더라도 train set이 test set이 되는 경우를 방지하기 위해서
loc: 행의 순서대로 select
from sklearn.model_selection import train_test_split train_set, test_set = train_test_split(housing, test_size=0.2, random_state=42)사이킷런의 train_test_split 함수
housing["median_income"].hist()
실행결과 housing["income_cat"] = pd.cut(housing["median_income"], bins=[0., 1.5, 3.0, 4.5, 6., np.inf], labels=[1, 2, 3, 4, 5])cut 함수: 나눌 구역을 정함
housing["income_cat"].value_counts() housing["income_cat"].hist()
실행결과 왼쪽에 편향되었던 그래프가 조금 더 종 모양에 가까워짐
from sklearn.model_selection import StratifiedShuffleSplit split = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42) for train_index, test_index in split.split(housing, housing["income_cat"]): strat_train_set = housing.loc[train_index] strat_test_set = housing.loc[test_index]strat_test_set["income_cat"].value_counts() / len(strat_test_set) housing["income_cat"].value_counts() / len(housing)테스트 셋과 트레이닝 셋의 결과가 거의 똑같음 -> 왜곡 방지
문제
- 회귀 문제에서 예측에 사용할 특성이 여러개인 경우 이를 [ ] 회귀 문제라 하며 각 구역마다 하나의 값을 예측하는 문제를 [ ] 회귀 문제라 한다. 구역마다 여러 값을 예측한다면 [ ] 회귀 문제이다.
- 데이터 스누핑 편향이란?
- stratified sampling이란?
- 데이터프레임의 행 또는 열을 삭제하는 판다스의 메서드는?
- 사이킷런의 train_test_split 메서드는 데이터셋을 여러 서브셋으로 나누는 함수이다. housing 데이터프레임을 test size 0.2, 난수 초기값을 42로 설정하여 분할하려 한다면 밑의 빈칸을 어떻게 채워야하는가?
from sklearn.model_selection import train_test_split train_set, test_set = train_test_split([빈칸],[빈칸],[빈칸])'핸즈온머신러닝' 카테고리의 다른 글
핸즈온 머신러닝[3] 분류(2) (0) 2022.05.05 핸즈온 머신러닝[3] 분류(1) (0) 2022.05.04 핸즈온 머신러닝[2] 머신러닝 프로젝트 처음부터 끝까지(3) (0) 2022.04.28 핸즈온 머신러닝[2] 머신러닝 프로젝트 처음부터 끝까지(2) (0) 2022.04.25 핸즈온 머신러닝[1] 한눈에 보는 머신러닝 (0) 2022.04.23