-
핸즈온 머신러닝[1] 한눈에 보는 머신러닝핸즈온머신러닝 2022. 4. 23. 20:30
https://www.youtube.com/watch?v=kpuRasV_Q9k&list=PLJN246lAkhQjX3LOdLVnfdFaCbGouEBeb&index=1
1.4 머신러닝 시스템의 종류
- 훈련 감독 방법: 지도 학습, 비지도 학습, 준지도 학습, 강화 학습
- 훈련 시점: 온라인 학습과 배치 학습
- 모델 생성: 사례 기반 학습과 모델 기반 학습
지도 학습: 정답이 있는 경우
- 선형 회귀
- 로지스틱 회귀
- 서포트 벡터 머신
- 결정 트리와 앙상블
- 신경망
비지도 학습: 정답이 없는 경우
- k-평균
- DBSCAN
- 가우시안 혼합
- 오토인코더
준지도 학습: 정답이 일부만 있는 경우
강화 학습: 행동의 보상이 있는 경우
온라인 학습
- 적은 데이터를 사용해 점진적으로 훈련
- 실시간 시스템이나 메모리가 부족한 경우에 사용
배치 학습
- 전체 데이터를 사용해 오프라인에서 훈현
- 컴퓨팅 자원이 풍부한 경우에 사용
사례 기반 학습
- 샘플을 기억하는 것이 훈련
- 예측을 위해 샘플 사이의 유사도를 측정
모델 기반 학습
- 샘플을 사용해 모델을 훈련
- 훈련된 모델을 사용해 예측
모델 기반 학습 예제
# Python ≥3.5 이상이 권장됩니다 import sys assert sys.version_info >= (3, 5)파이썬 버전이 2.5 이상인지 확인
# Scikit-Learn ≥0.20 이상이 권장됩니다 import sklearn assert sklearn.__version__ >= "0.20"sklearn 버전이 0.20 이상인지 확인
def prepare_country_stats(oecd_bli, gdp_per_capita): oecd_bli = oecd_bli[oecd_bli["INEQUALITY"]=="TOT"] oecd_bli = oecd_bli.pivot(index="Country", columns="Indicator", values="Value") gdp_per_capita.rename(columns={"2015": "GDP per capita"}, inplace=True) gdp_per_capita.set_index("Country", inplace=True) full_country_stats = pd.merge(left=oecd_bli, right=gdp_per_capita, left_index=True, right_index=True) full_country_stats.sort_values(by="GDP per capita", inplace=True) remove_indices = [0, 1, 6, 8, 33, 34, 35] keep_indices = list(set(range(36)) - set(remove_indices)) return full_country_stats[["GDP per capita", 'Life satisfaction']].iloc[keep_indices]pandas - dataframe
INEQUALITY 가 TOT가 아닌 경우를 제외함
pivot - 피벗 테이블
데이터 프레임에서 두 개의 열을 이용하여 행/열 인덱스 reshape된 테이블을 의미한다
새로운 테이블에서 새로운 기준으로 집계

# 주피터에 그래프를 깔끔하게 그리기 위해서 %matplotlib inline import matplotlib as mpl mpl.rc('axes', labelsize=14) mpl.rc('xtick', labelsize=12) mpl.rc('ytick', labelsize=12)label 사이즈 조절, %matplotlib inline 의 역할은 notebook을 실행한 브라우저에서 바로 그림을 볼 수 있게 해주는 것
# 데이터 다운로드 import urllib.request DOWNLOAD_ROOT = "https://raw.githubusercontent.com/rickiepark/handson-ml2/master/" os.makedirs(datapath, exist_ok=True) for filename in ("oecd_bli_2015.csv", "gdp_per_capita.csv"): print("Downloading", filename) url = DOWNLOAD_ROOT + "datasets/lifesat/" + filename urllib.request.urlretrieve(url, datapath + filename)코랩에서 실행하기 때문에 가상서버에 데이터를 다운로드 옆의 폴더 파일에서 확인할 수 있음
# 예제 코드 import matplotlib.pyplot as plt import numpy as np import pandas as pd import sklearn.linear_model # 데이터 적재 oecd_bli = pd.read_csv(datapath + "oecd_bli_2015.csv", thousands=',') gdp_per_capita = pd.read_csv(datapath + "gdp_per_capita.csv",thousands=',',delimiter='\t', encoding='latin1', na_values="n/a") # 데이터 준비 country_stats = prepare_country_stats(oecd_bli, gdp_per_capita) X = np.c_[country_stats["GDP per capita"]] y = np.c_[country_stats["Life satisfaction"]] # 데이터 시각화 country_stats.plot(kind='scatter', x="GDP per capita", y='Life satisfaction') plt.show() # 선형 모델 선택 model = sklearn.linear_model.LinearRegression() # 모델 훈련 model.fit(X, y) # 키프로스에 대한 예측 X_new = [[22587]] # 키프로스 1인당 GDP print(model.predict(X_new)) # 출력 [[ 5.96242338]]판다스의 read_csv 함수로 데이터를 불러옴
np.c: 여러개의 numpy 배열을 하나의 행으로 붙여줌
[1,2,3], [4,5,6] -> [[1,4],[2,5],[3,6]]
[1,2,3] -> [[1],[2],[3]]
sklearn에서 관습적으로 입력데이터는 이차원이므로 행렬처럼 생각하고 타깃데이터(맞춰야할 정답)는 일차원 배열로 생각하기 때문에 X는 대문자 y는 소문자로 쓴다.
산점도와 키프로스의 삶의 만족도에 대한 예측값
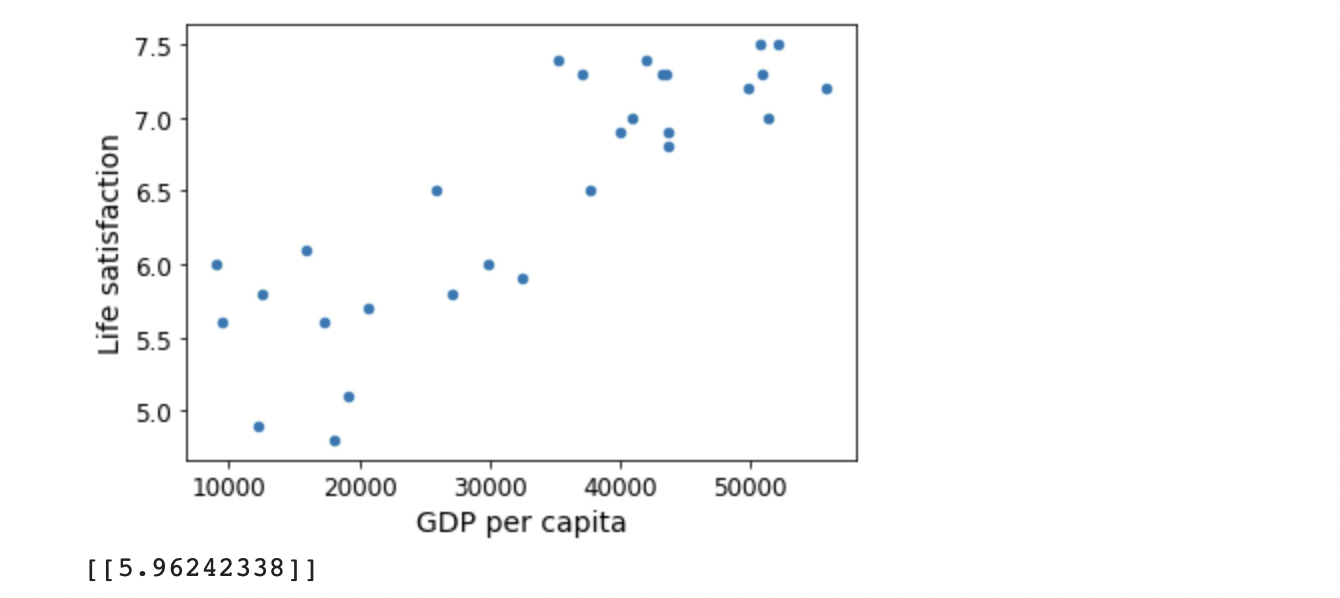
#키프로스의 삶의 만족도를 예측한 결과를 산점도에 포함 plt.scatter(X,y) plt.scatter(22587,5.96) plt.show()
요약
1. 데이터 준비(특성, 타깃)
2. 모델 선택(선형 회귀)
3. 모델 훈련(fit 메서드 호출)
4. 새로운 데이터에 대한 예측(prediction) 또는 추론(inference)
머신러닝의 주요 도전 과제
- 충분하지 않은 양의 훈련 데이터
- 대표성 없는 훈련 데이터 - 샘플링 잡음, 샘플링 편향
- 낮은 품질의 데이터
- 관련 없는 특성 - 특성 공학
- 과대적합, 과소적합
- 테스트 세트와 검증 세트 - 하이퍼파라미터
- 훈련-개발 세트
'핸즈온머신러닝' 카테고리의 다른 글
핸즈온 머신러닝[3] 분류(2) (0) 2022.05.05 핸즈온 머신러닝[3] 분류(1) (0) 2022.05.04 핸즈온 머신러닝[2] 머신러닝 프로젝트 처음부터 끝까지(3) (0) 2022.04.28 핸즈온 머신러닝[2] 머신러닝 프로젝트 처음부터 끝까지(2) (0) 2022.04.25 핸즈온 머신러닝[2] 머신러닝 프로젝트 처음부터 끝까지(1) (0) 2022.04.24