-
Attention Is All You Need (Transformer) 논문 설명자연어처리 2024. 3. 6. 13:43
https://arxiv.org/abs/1706.03762
Attention Is All You Need
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new
arxiv.org

[출처] : https://github.com/ndb796/Deep-Learning-Paper-Review-and-Practice/blob/master/lecture_notes/Transformer.pdf 1. RNN과 LSTM
- Seq2Seq 문제를 풀기 위해서는 input의 길이와는 상관 없이 입력을 받을 수 있는 모델이 필요하다.
- 이를 위해 나온 것이 RNN 모델이다. RNN은 회귀적 (recursive)으로, 이전 time step에서의 hidden state를 입력으로 받아 업데이트하는 방식으로 구성되어있다.
- RNN은 매 타입 스텝마다 동일한 파라미터를 사용하므로, generalization에 유리하며, 다양한 길이의 입력을 받을 수 있다는 장점이 있다.


- 그러나 RNN 모델에는 큰 문제점이 있다. 바로 Vanishing / Exploding Gradient 로 이는 RNN 모델에서 시퀀스가 길어지면 backpropagation 과정에서 특정 time step에서 gradient가 소실되거나 너무 커지는 문제이다.
- LSTM (Long Short Term Memory)이라는 모델은 Input Gate, Forget Gate, Output Gate 구조를 통해 RNN의 문제를 해결하였다. 이 게이트들은 중요한 정보를 유지하거나 버리는데 도움을 주어서 LSTM이 Long-Term Dependency를 효과적으로 학습하고 보존할 수 있도록 한다.
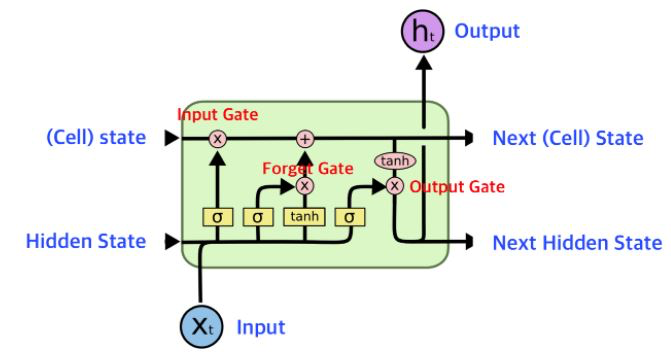

[출처] : StatQuest with Josh Starmer - Long Short-Term Memory (LSTM), Clearly Explained https://www.youtube.com/watch?v=YCzL96nL7j0 2. seq2seq with attention
- Encoder-Decoder 구조는 입력 시퀀스를 인코딩하여 고정된 길이의 vector로 임베딩하고 이러한 context vector를 다시 디코딩하여 출력 시퀀스를 생성하는 식으로 동작하며 seq2seq 문제에서 사용된다.

이미지 출처: [NLP] Encoder∙Decoder 구조와 Seq2Seq, Seq2Seq with Attention (https://velog.io/@nkw011/seq-to-seq) - seq2seq 구조는 한정된 길이의 벡터 (Context Vector)를 이용해 입력 sequence의 모든 정보를 담기 때문에 입력 정보의 유실이 일어난다는 문제가 있다. LSTM도 이러한 문제를 완벽하게 극복하진 못했으며, 이를 해결하기 위해 나온 것이 attention mechanism이다.
- 어텐션은, 입력 시퀀스에서 context vector를 만들지 않고, 매 스탭마다 인코더에서 디코더가 참고할 hidden state를 출력하고, 디코더는 관련이 깊은 입력 부분에 초점을 맞추어 예측을 진행한다.
- 이를 위해, 디코더에서, 각각의 Decoding step이 각각의 입력 단계의 인코딩에 접근할 수 있다. 그리고 similarity score와 softmax 함수를 사용하여 각각의 인코딩된 입력 단어들을 몇 퍼센트씩 써서 다음 출력값을 예측할 것인지 결정한다.
- Attention 과정에 대해서 잘 설명: https://velog.io/@nkw011/seq-to-seq
velog
velog.io
3. Attention Is All You Need
- Transformer 논문은 여기서 더 나아가서 LSTM, RNN을 완전히 없애고, Attention Mechanism만을 사용하여, LSTM, RNN 특성상 Parrallel 한 연산이 불가능한 문제를 해결하였으며, SOTA 성능을 달성하였다.
- 모델 구조는 다음과 같다.
- 인코더와 디코더는 각각 동일한 모듈 여섯개의 stack으로, 인코더는 Multi-Head Attention과 Feed Forward layer가 있고 여기에 각각 Normalization과 residual connection을 적용한다.
- 디코더도 비슷한 구조를 가지고 있지만, Multi-Head Attention에서 인코더의 Key와 Value를 사용하여 계산하며, Masked Multi-Head Attention에서는 마스킹을 사용하여 특정 위치에서 예측을 수행할 때, 그 위치 이후에 있는 정보는 고려하지 않도록 한다.
- 이는, 디코더에서 예측하려는 특정 위치 이후의 정보를 고려하게 되면, prediction 해야할 정보를 컨닝하는 것과 동일한 효과가 생기기 때문이다.

- Transformer에서는 self-attention을 scaled dot-product로 구현한다. 이는 다음과 같이 네가지 단계로 구성된다.
더보기- 각 토큰 임베딩을 query, key, value 세 개의 벡터로 투영한다.
- 유사도 함수(dot product)를 사용하여 query 벡터와 key 벡터가 서로 얼마나 관련되는지 계산함으로써 어텐션 점수를 구한다. 이 과정으로 인해 n개의 입력 토큰이 있는 시퀀스의 경우 크기가 nxn인 어텐션 점수 행렬이 만들어진다.
- 어텐션 가중치를 계산한다. 일반적으로 dot product는 임의의 큰 수를 만들기 때문에 훈련 과정이 불안정해진다. 이를 처리하기 위해 어텐션 점수에 scaling factor를 곱해 분산을 정규화하고 softmax 함수를 적용해 모든 열의 합이 1이 되도록 한다. 이를 통해 만들어진 nxn 행렬에는 어텐션 가중치 w_ij 가 만들어진다.
- 어텐션 가중치를 value 벡터와 곱해서 나온 값을 통해 토큰 임베딩을 업데이트한다.
아래의 코드를 통해 어텐션 가중치를 시각화할 수 있다.
from transformers import AutoTokenizer from bertviz.transformers_neuron_view import BertModel from bertviz.neuron_view import show model_ckpt = "bert-base-uncased" tokenizer = AutoTokenizer.from_pretrained(model_ckpt) model = BertModel.from_pretrained(model_ckpt) text = "When she arrived, it was like sunlight falling into a dim, glummy room. She was absolutely breathtaking." show(model, "bert", tokenizer, text, display_mode="light", layer=0, head=8)
- 또한, Single Attention을 수행하는 대신에, Multi-Head Attention을 통해 각기 다르게 학습된 linear projection을 사용하여 h번 linear projection된 Q, K, V를 parallel하게 Attention을 수행하고 이를 Concat한 다음 다시 linear projection을 수행한다.
- 이를 통해 모델이 각기 다른 subspace에서 표현된 더 풍부한 정보를 사용할 수 있도록 했다고 한다.

- 멀티 헤드 어텐션을 코드로 구현하면 아래와 같다.
def scaled_dot_product_attention(query, key, value): dim_k = query.size(-1) scores = torch.bmm(query, key.transpose(1,2)) / sqrt(dim_k) weights = F.softmax(scores, dim=-1) return weights class AttentionHead(nn.Module): def __init__(self, embed_dim, head_dim): super().__init__() self.q = nn.Linear(embed_dim, head_dim) self.k = nn.Linear(embed_dim, head_dim) self.v = nn.Linear(embed_dim, head_dim) def forward(self, hidden_state): attn_outputs = scaled_dot_product_attention( self.q(hidden_state), self.k(hidden_state), self.v(hidden_state) ) return attn_outputs class MultiHeadAttention(nn.Module): def __init__(self, config): super().__init__() embed_dim = config.hidden_size num_heads = config.num_attention_heads head_dim = embed_dim // num_heads self.heads = nn.ModuleList( [AttentionHead(embed_dim, head_dim) for _ in range(num_heads)] ) self.output_linear = nn.Linear(embed_dim, embed_dim) def forward(self, hidden_state): x = torch.cat([h(hidden_state) for h in self.heads], dim=-1) x = self.ouput_linear(x) return x- Transformer는 RNN 구조를 전혀 사용하지 않았기 때문에 Sequence 정보가 없다. 따라서 별도로 sequence 정보를 추가해주기 위해 positional encoding을 사용한다. 이 논문에서는 다른 주파수를 갖는 sine, cosine 함수를 사용하여 위치 정보를 인코딩하였다.
class PositionalEncoding(nn.Module): def __init__(self, hidden_size, max_position_embedding=200): super(PositionalEncoding, self).__init__() self.register_buffer('pos_table', self._get_sinusoid_encoding_table(max_position_embedding, hidden_size)) def _get_sinusoid_encoding_table(self, max_position_embedding, hidden_size): ''' Sinusoid position encoding table ''' def get_position_angle_vec(position): return [position / np.power(10000, 2 * (hid_j // 2) / hidden_size) for hid_j in range(hidden_size)] sinusoid_table = np.array([get_position_angle_vec(pos_i) for pos_i in range(max_position_embedding)]) sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2]) # dim 2i sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2]) # dim 2i+1 return torch.FloatTensor(sinusoid_table).unsqueeze(0) def forward(self, x): return x + self.pos_table[:, :x.size(1)].clone().detach() position_enc = PositionalEncoding(1000) x = torch.rand(1, 200, 1000) x = position_enc(x)4. results
- 아래는 English-to-German translation task에 대해서 다른 모델들과 성능을 비교한 실험이다.
- Transformer가 다른 모델들에 비해서 높은 성능을 가지면서 training cost 또한 낮은 것을 볼 수 있다.

[참고문헌]
- 루이스 턴스톨, 레안드로 폰 베라, 토마스 울프, 『트랜스포머를 활용한 자연어 처리』, 한빛미디어(2022)
'자연어처리' 카테고리의 다른 글
[NLP-tensorflow] Training an AI to create poetry (NLP Zero to Hero - Part 6) (0) 2022.06.08 [NLP-tensorflow] Long Short Term Memory for NLP (0) 2022.06.08 [NLP-tensorflow] ML with Recurrent Neural Networks (0) 2022.06.08 [NLP-tensorflow] Part 3 Training a model to recognize sentiment in text (0) 2022.06.06 [NLP-tensorflow] Part 2 Turning sentences into data (0) 2022.06.06