-
[NLP-tensorflow] Part 3 Training a model to recognize sentiment in text자연어처리 2022. 6. 6. 15:18
https://www.youtube.com/watch?v=Y_hzMnRXjhI&list=PLQY2H8rRoyvzDbLUZkbudP-MFQZwNmU4S&index=3
문장이 sarcasitic 한지 안한지 classifer로 분류.
is_sarcastic: 1-sarcastic, 0-otherwise
headline: the headline of the news article
article_link: link to the original news article. Useful in collecting supplementart data
파일이 JSON 형식이므로 파이썬 list 형태로 바꾸어주어야함
import json with open("sarcasm.json", 'r') as f: # file open and close datastore = json.load(f) sentences = [] lables = [] urls = [] for items in datastore: sentences.append(item['headline']) labels.append(item['is_sarcastic']) urls.appedn(item['article_link])from tensorflow.keras.preprocessing.text import Tokenizer from tensorflow.keras.preprocessing.sequence import pad_sequences tokenizer = Tokenizer(oov_token="<OOV>") tokenizer.fit_on_texts(sentences) word_index = tokenizer.word_index) sequences = tokenizer.texts_to_sequences(sentences) padded = pad_sequences(sequences, padding='post') print(padded[0]) print(padded.shape)Some of words in word index:
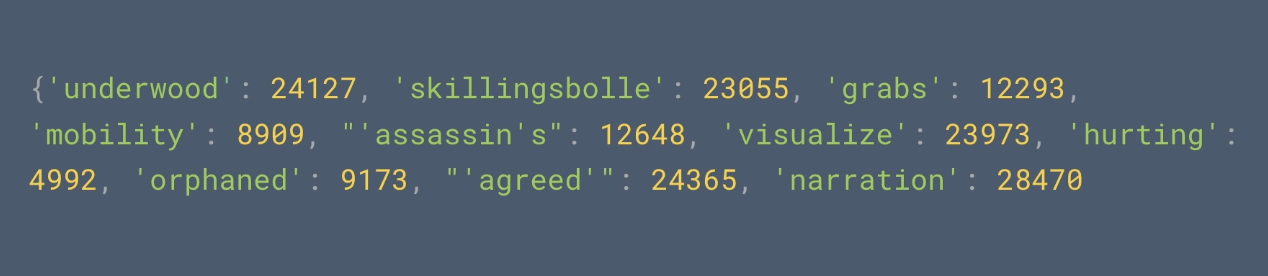
위의 코드 출력 결과:

하지만 위의 코드는 training, test data가 분리되어있지 않음 따라서 분리한 코드를 작성 ->
tokenizer = Tokenizer(num_words=vocab_size, oov_token=oov_tok) tokenizer.fit_on_texts(trainin_sentences) word_index = tokenizer.word_index training_sequences = tokenizer.texts_to_sequences(training_sentences) training_padded = pad_sequences(training_sequences, maxlen=max_length, padding=padding_type, truncating=trunc_type) testing_sequences = tokenizer.texts_to_sequences(testing_sentences) testing_padded = pad_sequences(testing_sequences, maxlen=max_length, padding=padding_type, truncating=trunc_type)그렇다면 sarcastic, not sarcastic 한 문장을 어떻게 구별해내고 분리할 것인가?
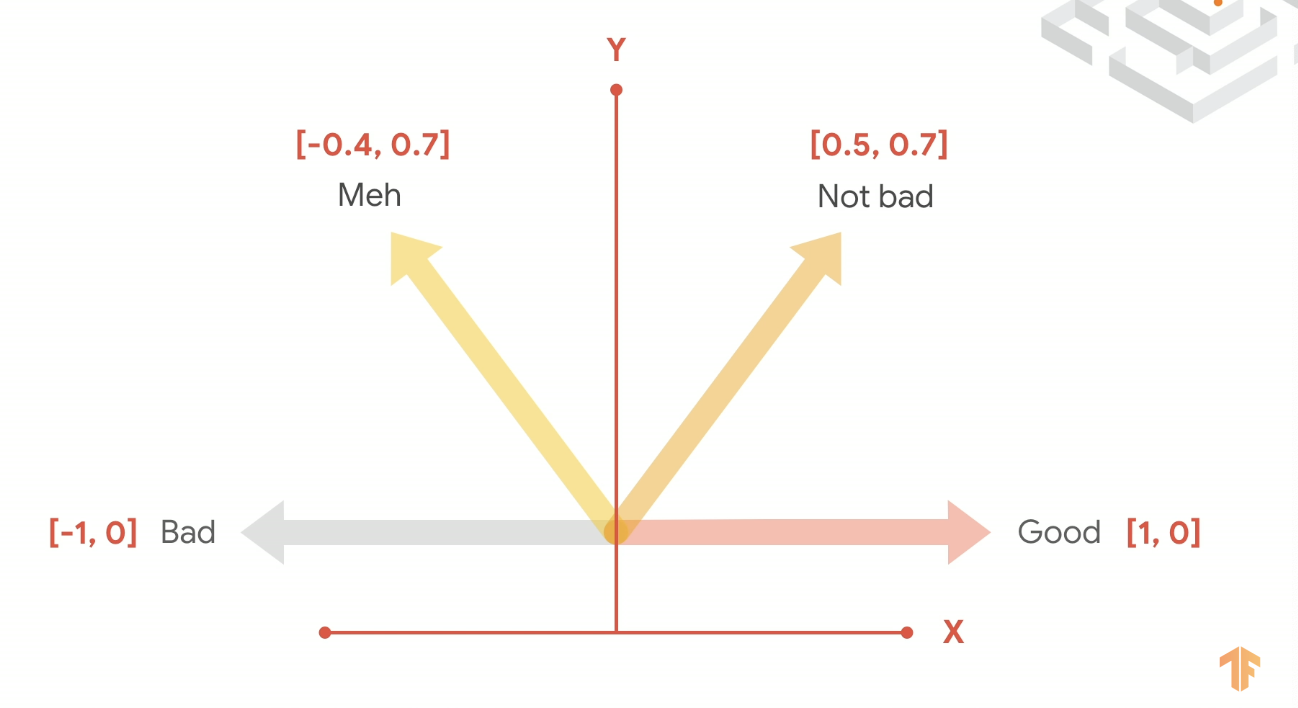
만약 우리가 데이터를 좋고 나쁨으로 분류한다면 다음과 같이 2차원의 그래프로 나타낼 수 있고 벡터의 방향을 통해 어느 쪽에 더 가까운지 구별할 수 있다.
이러한 과정을 embedding이라고 한다.
model = tf.keras.Sequential([ tf.keras.layers.Embedding(vocab_size, embedding_dim, input_length=max_length), tf.keras.layers.GlobalAveragePooling1D(), tf.keras.layers.Dense(24, activation='relu'), tf.keras.layers.Dense(1, activation='sigmoid') ]) model.compile(loss='binary_crossentrophy',optimizer='adam',metrics=['accuracy']) num_epochs = 30 history = model.fit(training_padded, training_labels, epochs=num_epoches, validation_data=(testing_padded, testing_labels), verbose=2)
새로운 문장에 적용하는 방법:
sentences = [ "granny starting to fear spiders in the garden might be real", "the weather today is bright and sunny" ] sequences = tokenizer.texts_to_sequences(sentence) padded = pad_sequencces(sequences, maxlen=max_length, padding=padding_type, truncating=trunc_type) print(model.predict(padded))
첫번째 문장: sarcastic 확률이 높음, 두번째 문장: 확률이 낮음
'자연어처리' 카테고리의 다른 글
[NLP-tensorflow] Training an AI to create poetry (NLP Zero to Hero - Part 6) (0) 2022.06.08 [NLP-tensorflow] Long Short Term Memory for NLP (0) 2022.06.08 [NLP-tensorflow] ML with Recurrent Neural Networks (0) 2022.06.08 [NLP-tensorflow] Part 2 Turning sentences into data (0) 2022.06.06 [NLP-Tensorflow] Part 1 Tokenization (0) 2022.06.06