-
[NLP-tensorflow] Part 2 Turning sentences into data자연어처리 2022. 6. 6. 14:27
https://www.youtube.com/watch?v=r9QjkdSJZ2g&list=PLQY2H8rRoyvzDbLUZkbudP-MFQZwNmU4S&index=2
Creating sequences of numbers from your sentences and using tools to process them to make them ready for teaching neural networks
from tensorflow.keras.preprocessing.text import Tokenizer sentences = [ 'I love my dog', 'I love my cat', 'You love my dog', 'Do you think my dog is amazing?' ] tokenizer = Tokenizer(num_words = 100) tokenizer.fit_on_texts(sentences) word_index = tokenizer.word_index sequences = tokenizer.texts_to_sequences(sentences) # creates sequences of tokens representing each sentence. print(word_index) print(sequences)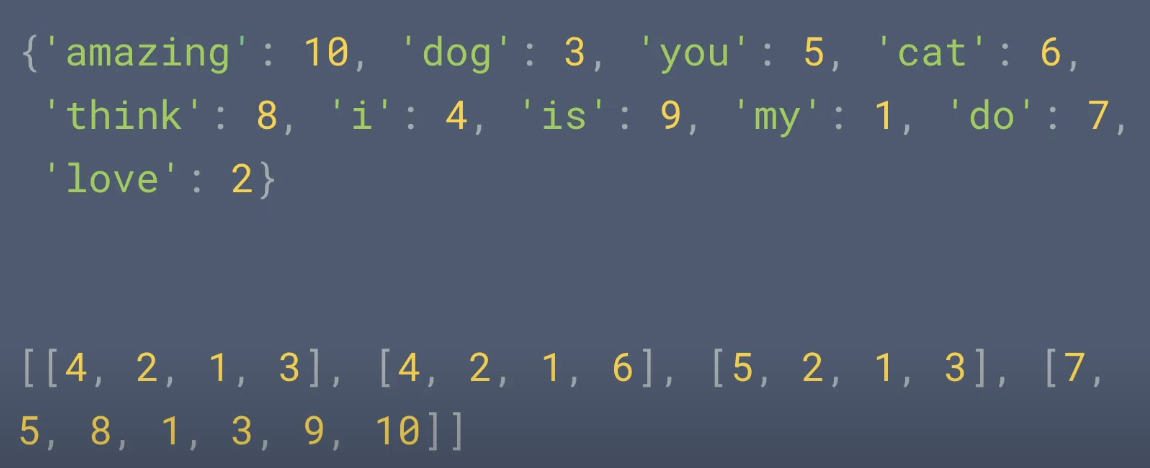
만약에 word index에 존재하지 않는 단어를 포함하는 문장을 시퀀싱하려고 하면 어떻게 될까?
test_data = [ 'I really love my dog', 'my dog loves my manaty' ] test_seq = tokenizer.texts_to_sequences(test_data) print(test_seq)[[4,2,1,3], [1,3,1]]
-> word index에 포함되지 않은 단어는 제외되게 된다.
밑의 코드와 같이 oov(out of vocaulary) parameter를 세팅하주면 tokenizer가 그것으로 토큰을 생성하고 word index에 존재하지 않은 단어를 oov 토큰으로 표시해준다.
tokenizer = Tokenizer(num_words=100, oov_token="<OOV>")위의 문장을 다시 sequencing 해주면 다음과 같은 결과가 나온다.
위와 같이 하면 문장을 동일한 길이로 표시할 수 있다는 장점이 있다.

Padding
from tensorflow.keras.preprocessing.text import Tokenizer from tensorflow.keras.preprocessing.sequence import pad_sequence sentences = [ 'I love my dog', 'I love my cat', 'You love my dog!', 'Do you think my dog is amazing?' ] tokenizer = Tokenizer(num_words = 100, oov_token = "<OOV>") tokenizer.fit_on_texts(sentences) word_index = tokenizer.word_index sequences = tokenizer.texts_to_sequences(sentences) padded = pad_sequences(sequences) # pad our sequences print(word_index) print(sequences) print(padded)
padding with 0
padded = pad_sequences(sequences, padding='post',truncating='post',maxlen=5)
padding, maxlen 파라미터로 문장 길이와 0의 위치를 조정할 수 있음
또한, maxlen으로 문장 길이를 정할 때, 정해진 문장 길이보다 문장이 긴 경우 어디를 자를지 truncating 파라미터로 정할 수 있음
'자연어처리' 카테고리의 다른 글
[NLP-tensorflow] Training an AI to create poetry (NLP Zero to Hero - Part 6) (0) 2022.06.08 [NLP-tensorflow] Long Short Term Memory for NLP (0) 2022.06.08 [NLP-tensorflow] ML with Recurrent Neural Networks (0) 2022.06.08 [NLP-tensorflow] Part 3 Training a model to recognize sentiment in text (0) 2022.06.06 [NLP-Tensorflow] Part 1 Tokenization (0) 2022.06.06