-
OHEM 논문 읽기Computer Vision 2023. 3. 8. 17:55
논문 링크 : https://arxiv.org/pdf/1604.03540.pdf
목차
0. Abstract
1. Introduction
2. Related work
3. Overview of Fast R-CNN
4. Our approach
5. Analyzing online hard example mining
0. Abstract
본 논문에서는 online hard example mining (OHEM) 알고리즘을 제시합니다. 이는 영역 기반(region-based) ConvNet detector를 훈련하기 위한 간단하면서도 놀랍도록 효과적인 알고리즘입니다. Detection 데이터셋에는 어려운 예제에 비해 쉬운 예제가 압도적으로 많습니다. 따라서 어려운 예제를 자동으로 선택하면 훈련이 보다 효과적이고 효율적일 수 있습니다. OHEM은 일반적으로 사용되는 여러 휴리스틱과 하이퍼파라미터를 제거하는 간단하고 직관적인 알고리즘입니다. 그러나 더 중요한 것은 PASCAL VOC 2007 및 2012와 같은 벤치마크에서 성능을 상당히 향상시킨다는 점입니다. 데이터셋이 커질수록 그리고 어려워질 수록 OHEM의 효과는 증대됩니다. 더해서, 이 분야의 발전과 결합해서 OHEM은 PASCAL VOC 2007 및 2012에서 각각 78.9%와 76.3%의 SOTA 결과를 도출했습니다.
1. Introduction
Object detector는 종종 객체 검출을 이미지 분류 문제로 감소시켜 훈련됩니다. 이는 이미지 classification 작업에서는 발견되지 않는 새로운 도전 과제를 만듭니다. 바로 훈련 세트가 클래스가 있는 객체의 수와 배경의 수 사이에 큰 불균형으로 구분된다는 것입니다. 이러한 불균형은 DPM과 같은 슬라이딩 윈도우 객체 검출기의 경우 1개의 객체에 대해 100,000 개의 배경 예제와 같이 극단적일 수 있습니다. region proposal 방식은 이 문제를 어느정도 완화하지만 불균형 비율은 여전히 높을 수 있습니다 (예 : 70:1). 이러한 어려움을 해소하면 더 빠른 학습과 더 높은 정확도를 얻을 수 있습니다.
강아지를 검출하는 경우에, 오른쪽 그림과 같이 강아지를 포함하고 있는 상자는 클래스가 있는 객체를 포함하고 있지만, 왼쪽 그림의 경우에는 많은 상자가 강아지를 포함하지 않는 배경만을 포함하고 있는 것을 알 수 있습니다.

sliding window 방식은 이미지를 격자 모양의 여러 개의 작은 윈도우로 분할하고, 각각의 윈도우에서 object가 존재하는지를 확인하는 방법입니다.
region proposal 방식은 이미지 내에서 물체가 존재할 가능성이 높은 bounding box (region) 후보를 생성하는 알고리즘입니다. 이 방식은 이미지 내에서 가능한 모든 위치를 검사하는 것이 아니라, 물체가 존재할 가능성이 높은 위치를 제한하여 계산 효율성을 높입니다. region proposal은 일반적으로 selective search와 같은 알고리즘을 사용하여 생성되며, 이후에는 각각의 region에 대해 object detection을 수행합니다.
이는 새로운 도전이 아니며, Bootstrapping(하드 네거티브 마이닝)이라는 솔루션이 적어도 20년 이상 존재해왔습니다. 이 전략은 현재 example 집합을 기반으로 detection 모델을 업데이트하고, 그 업데이트된 모델을 사용하여 부트 스트랩된 훈련 세트에 추가할 새로운 false positive를 찾는 반복적인 훈련 알고리즘으로 이어집니다.

부트 스트래핑은 지난 수십 년간 널리 사용되어 왔습니다. 이 알고리즘은 하드 네거티브 마이닝으로 자주 언급되며, 객체 검출을 위해 SVM을 훈련시킬 때 자주 사용됩니다.
negative example은 관심 물체를 포함하고 있지 않은 이미지 패치 또는 영역을 의미합니다. 하드 네거티브 마이닝은 모델이 positive라고 착각할 수 있는 어려운 negative들을 모으는 작업을 의미합니다.

hard negative mining 따라서 SOTA detector인 Fast R-CNN과 그 후속작(Faster R-CNN)이 부트 스트래핑을 사용하지 않는 것이 의아할 수 있습니다. 부트스트래핑을 사용하지 않는 이유는 온전히 online learning 알고리즘으로의 전환, 특히 수백만 가지 example에 대한 확률적 경사 하강(SGD)으로 훈련된 심층 ConvNets의 맥락에서 발생하는 기술적 어려움 때문입니다.
부트스트래핑은 앞서 언급한 방식에 의존합니다. (a) 어떤 기간 동안 고정된 모델이 사용되어 새로운 예제가 훈련 세트에 추가되도록 선택되며, (b) 그 다음, 어떤 기간 동안 고정된 훈련 세트로 모델이 훈련됩니다. SGD로 deep ConvNet 검출기를 훈련시키는 것은 일반적으로 수십만 번의 단계가 필요하며, 일부 iteration(반복)에서 모델을 몇 번 동안 고정하면 진행 속도가 크게 느려집니다.
본 논문에서는, deep ConvNets 기반의 최신 탐지 모델을 훈련시키기 위한 새로운 부트스트래핑 기술로 online hard example mining(OHEM)이라는 기술을 제안합니다. 이 알고리즘은 각 example의 현재 loss에 따라 결정되는 분포를 따라 훈련 예시를 샘플링하는 SGD의 단순한 변형입니다. 이 방법은 SGD 미니배치가 하나 또는 두 개의 이미지만으로 구성되지만, 수천 개의 후보 example이 포함된 detection의 구조를 활용합니다. 후보 example들은 다양하고 loss가 높은 인스턴스를 선호하는 distribution에 따라 샘플링됩니다. 그러나 그라디언트 계산(Backpropagation)은 모든 후보 중 일부만 사용하므로 여전히 효율적입니다. OHEM은 표준 Fast R-CNN 탐지 방법에 적용되며 기본 훈련 알고리즘과 비교하여 세 가지 이점을 보입니다.
- 영역 기반 ConvNets에서 일반적으로 사용되는 여러 가지 휴리스틱 및 하이퍼파라미터를 제거합니다.
- mAP(mean average precision)가 일관되게 향상됩니다.
- 학습 데이터셋이 커지고 더 어려워질 수록 그 효과가 증가합니다.
또한, OHEM을 통해 얻는 향상은 최근 물체 탐지 분야에서의 개선 사항, 예를 들어 Multi-scale 테스팅 및 iterative bounding-box regression과 함께 사용될때 상호 보완적입니다. 이러한 기술들과 결합하여, OHEM은 PASCAL VOC 2007 및 2012에서 78.9%와 76.3%의 SOTA 결과를 보입니다.
2. Related work
Hard example mining
보통 두 가지 Hard example mining 알고리즘이 일반적으로 사용됩니다.
첫번째 방법은 SVM을 최적화할 때 사용됩니다. 이 경우, 학습 알고리즘은 working set을 유지하고 working set에서 SVM을 수렴할 때까지 교육을 반복하고, 특정 규칙에 따라 일부 예제를 제거하고 다른 예제를 추가하여 working set을 업데이트합니다. 이 규칙은 올바르게 분류되는 "쉬운" 예제를 제거하고, "어려운" 새로운 예제를 추가합니다. 이 규칙을 적용하면 global SVM 솔루션이 나옵니다. 중요한 것은 working set이 보통 전체 학습 세트의 작은 하위 집합이라는 점입니다.
두 번째 방법은 SVM이 아닌 다른 모델에 사용되며, 얕은 신경망 및 부스팅 결정 트리를 비롯한 다양한 모델에 적용되었습니다.
이 알고리즘은 일반적으로 positive example 데이터셋과 무작위로 선택된 negative example 데이터셋으로 시작됩니다. 그런 다음 모델이 해당 데이터셋에서 수렴하도록 학습되고, 그 다음 더 큰 데이터셋에 적용하여 false positive를 수집합니다. 그런 다음, False positive가 학습 세트에 추가되고 모델이 다시 학습됩니다. 이 프로세스는 보통 한 번만 반복되며 수렴이 증명되진 않았습니다.
ConvNet-based object detection
OverFeat는 detection을 위한 슬라이딩 윈도우 검출 방법에 기반을 두고 있으며, 이는 아마도 가장 직관적이고 오래된 검색 방법 중 하나입니다. 반면 R-CNN은 region proposal을 사용하는데, 이는 selective search 알고리즘에 의해 인기를 얻었습니다. R-CNN 이후, SPPnet, MR-CNN 및 Fast R-CNN을 비롯한 region-based ConvNets에서 빠른 발전이 이루어졌으며, 본 논문의 연구는 Fast R-CNN에 기반을 두고 있습니다.
Hard example selection in deep learning
본 논문의 연구와 동시에 진행되는 최근 연구들은 딥 뉴럴넷 학습을 위해 hard example들을 선택합니다. 우리는 영역 기반 객체 탐지기(region-based object detector)를 위한 online hard example 선택 전략에 중점을 둡니다.
3. Overview of Fast R-CNN
FRCN은 이미지와 일련의 RoIs(Regions of Interest) 집합을 입력으로 받습니다. FRCN 네트워크 자체는 두 개의 순차적인 부분으로 나뉘어질 수 있습니다. 하나는 여러개의 컨볼루션(Convolution) 및 맥스 풀링(Max-pooling) 레이어를 가진 컨볼루션 네트워크이고, 다른 하나는 RoI-pooling 레이어, 여러 fully-connected (fc) 레이어 및 두 개의 loss 레이어를 가진 RoI 네트워크입니다.

추론 과정에서는, 주어진 이미지에 대해 컨볼루션 네트워크가 적용되어 컨볼루션 피쳐맵을 생성하며, 이 맵의 크기는 입력 이미지 크기에 따라 결정됩니다. 그런 다음, 각 object proposal에 대해 RoI-pooling 레이어가 proposal을 컨볼루션 피쳐맵에 투영하고 고정된 길이의 feature 벡터를 추출합니다. 각 featuer 벡터는 fc 레이어에 입력되며, 이 레이어는 최종적으로 두 개의 출력을 제공합니다: (1) 객체 클래스 및 배경에 대한 softmax 확률 분포, 그리고 (2) bounding box 재지정(regressed coordinates)을 위한 회귀(regression)된 좌표입니다.
본 논문에서 FRCN을 선택한 이유는 빠른 end-to-end 시스템이라는 점 외에도 여러 가지 이유가 있습니다. 첫째로, 기본적인 두 개의 네트워크 설정(conv 및 RoI)은 SPPnet 및 MR-CNN과 같은 최근 객체 탐지기에서도 사용되므로, 제안된 알고리즘이 보다 넓게 적용될 가능성을 가집니다. 둘째로, 기본 설정이 비슷하지만 FRCN은 conv 네트워크 전체를 학습할 수 있도록 해줍니다. SPPnet과 MR-CNN은 conv 네트워크를 고정시켜 놓기 때문에 이들과 차이가 있습니다. 마지막으로, SPPnet과 MR-CNN 모두 별도의 SVM 분류기를 학습시키기 위해 RoI 네트워크의 피쳐를 캐시해야 합니다(하드 네거티브 마이닝 사용). 그러나 FRCN은 RoI 네트워크 자체를 사용하여 필요한 분류기를 학습합니다.
3.1 Training
FRCN은 대부분의 딥 네트워크와 마찬가지로 확률적 경사 하강법(SGD)을 사용하여 학습됩니다. 각 example RoI의 loss는 classification log loss와 localization loss의 합으로 구성됩니다. RoI 간 conv 네트워크 계산을 공유하기 위해 SGD 미니배치는 계층적으로 생성됩니다. 각 미니배치에 대해, 데이터셋에서 N개의 이미지가 먼저 샘플링되고, 각 이미지에서 B/N개의 RoI가 샘플링됩니다. N = 2 및 B = 128로 설정하는 것이 실제로 잘 작동합니다. RoI 샘플링 절차는 몇 가지 휴리스틱을 사용하며, 이를 간단히 설명하겠습니다. 이 논문의 기여 중 하나는 이러한 휴리스틱 및 이들의 하이퍼파라미터를 제거한 것입니다.
Foreground RoIs
Foreground로 라벨링되는 RoI의 경우, 해당 RoI와 ground-truth 바운딩 박스와의 IoU(Intersection over Union) 값이 최소 0.5 이상이어야 합니다. 이는 PASCAL VOC 객체 검출 벤치마크의 평가 프로토콜에서 영감을 받은, 꽤 일반적인 설계 선택 사항입니다. R-CNN, SPPnet 및 MR-CNN의 SVM 하드 마이닝 절차에서도 동일한 기준이 사용됩니다. 본 논문에서도 동일한 설정을 사용합니다.
Foreground RoI는 실제로 객체를 포함하고 있는 RoI를 의미하며, Background RoI는 객체가 없는 RoI를 의미합니다.

Background RoIs
영역이 배경(bg)으로 라벨링되는 경우는, 해당 영역과 ground truth 사이의 최대 IoU(Intersection over Union)가 [bg lo, 0.5) 구간에 있는 경우입니다. bg lo 값으로는 FRCN과 SPPnet에서 모두 0.1을 사용하며, FRCN에서는 하드 네거티브 마이닝을 대략적으로 근사화하기 위한 것으로 가설을 제시하고 있습니다. 이는 일부 ground truth와 겹치는 영역이 헷갈리거나 어려운 경우일 가능성이 더 높다는 것을 가정하는 것입니다. 5.4 절에서 우리는 이러한 휴리스틱이 수렴 및 검출 정확도를 돕는다는 것을 보여주지만, 드물게 중요한 어려운 배경 영역을 무시하기 때문에 최적이 아니라는 것을 보여줍니다. 본 논문에서는 bg lo 임계값을 제거하는 방식을 사용합니다.
Balancing fg-bg RoIs
Section 1에서 설명한 데이터 불균형을 처리하기 위해 FRCN에서는 각 미니 배치에서 fg 대 bg 비율을 1 : 3의 목표 비율로 재조정하기 위해 배경 패치를 무작위로 언더샘플링하여 미니 배치의 25%가 fg RoI가되도록 하는 휴리스틱을 설계했습니다. 본 논문에서는 이것이 FRCN을 학습할 때 중요한 요소임을 알게 되었습니다. 이 비율을 제거하거나 늘리면 정확도가 약 3 mAP 감소하기 때문입니다. 본 논문에서 제시한 방법으로는 이 비율 하이퍼 파라미터를 부작용 없이 제거할 수 있습니다.
4. Our approach
본 논문에서 간단하지만 효과적인 Fast R-CNN 학습을 위한 online hard example mining 알고리즘을 제안합니다. SGD를 위해 미니 배치를 생성하는 현재의 방식 (3.1절)이 비효율적이고 최적화되지 않았다고 주장하며, 본 논문에서 제시한 방법이 더 나은 학습과 높은 테스트 성능 (mAP)을 보인다는 것을 입증합니다.
4.1 Online hard example mining
Hard example mining 알고리즘의 반복되는 단계를 상기해 보겠습니다.
(a) 일정 기간 동안 고정된 모델을 사용하여 활성화된 학습 집합에 추가할 새로운 예제를 찾는 단계
(b) 그런 다음 일정 기간 동안 모델이 고정된 활성 학습 집합에서 훈련되는 단계
R-CNN이나 SPPnet에서 학습되는 SVM 기반 객체 검출기의 경우, 단계 (a)는 active training set이 threshold 크기에 도달할 때까지 가변 이미지 수 (일반적으로 10 개 또는 100 개)를 검사하고, 그런 다음 단계 (b)에서 SVM이 수렴할 때까지 active training set으로 훈련합니다. 이러한 과정은 active training set이 모든 서포트 벡터를 포함할 때까지 반복됩니다. FRCN ConvNet 훈련에 유사한 전략을 적용하면, 10 개 또는 100 개의 이미지에서 예제를 선택하는 동안 모델 업데이트가 이루어지지 않기 때문에 학습 속도가 느려집니다.
SVM(Support Vector Machine) 기반 객체 검출기는 이미지에서 객체를 검출하기 위해 여러 단계로 이루어져 있습니다. 먼저 이미지에서 가능성 있는 객체 후보들을 찾아냅니다. 그 다음에는 각 객체 후보 영역이 실제로 객체인지 아닌지를 판별하기 위해 SVM 분류기를 사용합니다. SVM은 학습 데이터로부터 경계를 찾아내어 새로운 데이터를 분류하는 방식으로 작동합니다. SVM 기반 객체 검출기는 R-CNN, SPPnet 등의 알고리즘이 있습니다.
"active training set"은 현재 모델 학습을 위해 사용되고 있는 example들의 집합입니다.
본 논문에서의 주요한 관찰은 이러한 두 개의 반복되는 단계가 온라인 SGD를 사용하여 FRCN을 학습하는 방법과 결합될 수 있다는 것입니다. 각 SGD 반복이 작은 수의 이미지만 샘플링하지만, 각 이미지는 수천 개의 예제 RoI를 포함하고 있어서 임의로 샘플링된 하위 집합 대신 어려운 예제를 선택할 수 있다는 것이 핵심입니다. 이 전략은 모델을 한 번의 미니 배치에만 "동결"하기 때문에 SGD에 반복 과정을 적합하게 맞추며, 따라서 모델은 기본 SGD 접근 방식으로 정확히 자주 업데이트되며 학습이 지연되지 않습니다.
보다 구체적으로, OHEM 알고리즘은 다음과 같이 진행됩니다.
- 입력 이미지에서 SGD 반복 횟수 t에서 대해서, 우선 conv 네트워크를 사용하여 conv 피쳐 맵을 계산합니다.
- 그런 다음 RoI 네트워크는 이 피쳐 맵과 모든 입력 RoI (샘플링된 미니 배치가 아니라)를 사용하여 forward pass를 수행합니다. 이 단계에서는 RoI 풀링, 몇 개의 fc 레이어 및 각 RoI에 대한 loss 계산만이 필요합니다. loss는 현재 네트워크가 각 RoI에 대해 얼마나 잘 수행하는지를 나타냅니다.
- Hard example은 loss에 따라 입력 RoI를 정렬한 다음에, 현재 네트워크가 가장 잘 수행하지 못하는 B/N 개의 예제를 고름으로써 선택됩니다.
대부분의 forward 계산은 conv 피쳐 맵을 통해 RoI 간에 공유되므로 모든 RoI를 전달하기 위해 필요한 추가 계산은 비교적 적습니다. 또한, 모델 업데이트에 대해 일부 RoI만 선택되므로 backpropagation 이전과 같은 비용이 들지 않습니다.
그러나 한 가지 주의할 점이 있습니다. 매우 중첩된 동일한 위치의 RoI는 correlated loss를 가질 가능성이 높습니다. 또한 해상도 불일치 때문에 중복된 RoI는 Conv 피쳐맵에서 동일한 영역에 투영될 수 있으므로 loss가 중복 계산될 수 있습니다. 이러한 중복 및 상관된 영역을 처리하기 위해 NMS(Non maximal suppresion)를 사용하여 중복을 제거합니다. RoI 목록과 그들의 loss가 주어지면 NMS는 반복적으로 가장 높은 loss를 가진 RoI를 선택한 다음 선택된 영역과 중복되는 낮은 loss를 갖는 RoI를 제거하여 작동합니다. 매우 중첩된 RoI만을 억제하기 위해 느슨한 IoU 임계값 0.7을 사용합니다.
본 논문에서는 위에서 설명한 절차가 데이터 균형을 위해 fg-bg 비율이 필요로하지 않음을 주목합니다(3.1절에서 설명). 어떤 클래스가 무시되면 해당 클래스의 loss는 높은 확률로 샘플링될 때까지 증가할 것입니다. 일부 이미지에서는 fg RoI가 쉬운 경우, 네트워크는 미니 배치에서 bg 영역만 사용할 수 있으며, bg가 단순한 경우 (예 : 하늘, 잔디 등)에는 미니 배치가 완전히 fg 영역일 수 있습니다.
위에서 설명한 방법은 데이터 균형을 위해 fg-bg 비율이 필요하지 않다는 것을 강조합니다. 즉, 특정 클래스의 RoI들이 적게 나타난 경우, 해당 클래스의 loss 값이 증가하여 학습에 더 많은 비중을 두도록 합니다. 이를 통해 데이터 균형을 맞출 수 있습니다.
또한 이 단락에서는 네트워크가 이미지에서 fg RoI들을 쉽게 추출할 수 있는 경우, 네트워크가 배경(bg) 영역만 사용하여 미니배치를 생성할 수 있으며, 그 반대의 경우도 가능하다는 것을 언급합니다. 이를 통해 미니배치의 구성을 자유롭게 조절할 수 있으며, 이는 학습 효과를 높이는 데에 도움을 줍니다.
4.2 Implementation details
FRCN 검출기에서 OHEM을 구현하는 방법은 여러 가지가 있으며, 각각 다른 트레이드오프를 가지고 있습니다.
가장 간단한 방법은 loss 레이어를 수정하는 것입니다. loss 레이어는 모든 RoI에 대한 loss를 계산하며 이 loss를 기반으로 RoI를 선택하여 하드 RoI를 선택한 후 모든 하드가 아닌 RoI의 loss를 0으로 설정할 수 있습니다.
이 구현은 직관적이지만, 대부분의 RoI의 loss가 0이므로 그라디언트 업데이트가 없음에도 RoI 네트워크가 여전히 모든 RoI에 대해 메모리를 할당하고 backpropagation을 수행하기 때문에 효율적이지 않습니다 (현재 딥러닝 툴박스의 한계).
이를 극복하기 위해, 우리는 밑의 그림에 제시된 아키텍처를 제안합니다.
본 논문에서의 구현은 RoI 네트워크의 두 개 복사본을 유지합니다. 그 중 하나는 읽기 전용(read-only)입니다. 이것은 읽기 전용 RoI 네트워크(그림에서의 (a))가 일반 RoI 네트워크와 달리, 모든 RoI에 대해 forward pass만을 위해 메모리만 할당한다는 것을 의미합니다.
한 번의 SGD iteration에서, conv feature map이 주어지면, 읽기 전용 RoI 네트워크는 모든 입력 RoI (R) 에 대해 forward pass를 수행하고 loss를 계산합니다 (녹색 화살표). 그런 다음 Hard RoI 샘플링 모듈은 4.1절에서 설명한 프로시저를 사용하여 hard example을 선택합니다. 그리고 이것들은 일반 RoI 네트워크 (빨간색 화살표)의 입력으로 사용됩니다. 이 네트워크는 hard example에 대해서만 forward, backward pass를 수행하고 gradient를 축적하여 conv 네트워크에 전달합니다.
실제로, 모든 N개의 이미지에서 모든 RoI를 사용하므로, 읽기 전용 RoI 네트워크의 배치 크기는 |R|이고 일반 RoI 네트워크는 Section 3.1의 표준 B입니다.

우리는 Caffe 프레임워크를 사용하여 위에서 설명한 두 가지 옵션 모두를 구현합니다. FRCN에 따라 N = 2 (이는 |R| ≈ 4000을 결과로 가져옵니다) 및 B = 128을 사용합니다. 이러한 설정에서, 아키텍처는 첫 번째 옵션과 유사한 메모리 풋프린트를 가지지만 2배 이상 더 빠릅니다. 특별히 명시하지 않는 한, 이 논문에서는 위에서 설명한 아키텍처와 설정을 계속 사용할 것입니다.
5. Analyzing online hard example mining
이 섹션은 FRCN 학습에서 OHEM과 휴리스틱 샘플링 방법을 비교합니다.
5.1 Experimental setup
두 개의 표준 ConvNet 아키텍처인 VGGM과 VGG16을 사용하여 실험을 진행합니다. 이 실험은 모두 PASCAL VOC07 데이터셋에서 수행되며, 학습은 trainval 세트에서 진행되고 테스트는 test 세트에서 진행됩니다. 기본 설정을 FRCN에서 사용하는 것으로 지정하고, 초기 학습률은 0.001이고 30k 반복마다 학습률을 0.1로 감소시킵니다.
5.2 OHEM vs. heuristic sampling

Table 1에서 보이는 FRCN(1-2행)은 하드 마이닝을 위한 휴리스틱으로 bg lo = 0.1을 사용합니다(3.1절). 이 휴리스틱의 중요성을 검증하기 위해 bg lo = 0으로 FRCN을 실행했습니다. Table 1(3-4행)은 VGGM의 경우 mAP가 2.4점 감소하고, VGG16의 경우 거의 변화하지 않음을 보여줍니다. 이제 이를 OHEM과 비교해봅시다(11-13행). OHEM은 VGGM에 대해 휴리스틱 없이 4.8점 향상된 mAP를 보여주며, 휴리스틱으로 실행했을 때 대비 2.4점 향상됩니다.
5.3 Robust gradient estimates
배치 당 N = 2 이미지만 사용하는 것은 이미지의 RoI가 상호 연관성이 높을 수 있으므로 불안정한 그래디언트와 수렴 속도가 느려질 수 있다는 우려가 있습니다. FRCN은 이것이 실제로 문제가 되지 않았다고 보고했습니다. 그러나 이 정보는 우리의 학습 절차에 대한 우려를 일으킬 수 있습니다. 왜냐하면 우리는 동일한 이미지에서 loss가 높은 example을 사용하므로 그 결과 RoI는 상관 관계가 더 높아질 수 있기 때문입니다. 이 우려를 해결하기 위해, 우리는 N = 1로 실험하여 상관 관계를 높이고 우리의 방법을 break하기 위해 노력했습니다.
Table 1 (rows 5-6, 11)에서 볼 수 있듯이 본래의 FRCN의 성능은 N = 1로 인해 약 1 포인트 하락하지만, 우리의 교육 절차를 사용할 때는 mAP가 거의 동일합니다. 이는 GPU 메모리 사용량을 줄이기 위해 배치 당 이미지를 적게 필요로 할 때 OHEM이 견고하다는 것을 보여줍니다.
5.4 Why just hard examples, when you can use all?
OHEM은 이미지 내 모든 RoI를 고려하고 hard example을 선택하는 것이 중요하다는 가설에 기반합니다. 그러나 만약 모든 RoI를 사용하여 학습을 진행한다면 어떨까요? easy example은 loss가 적기 때문에 그래디언트에 큰 기여를 하지 않으며, 학습은 자동으로 어려운 예제에 초점을 맞출 것입니다. 이 옵션을 비교하기 위해, B = 2048 큰 미니배치 크기로 표준 FRCN 학습을 실행하였습니다. 이 실험에서는 더 큰 미니배치를 사용하기 때문에 이러한 변경에 대한 학습률을 조정하는 것이 중요합니다. 본 논문에서는 VGG16의 경우 0.003, VGGM의 경우 0.004로 학습률을 증가시켜 최적 결과를 찾았습니다. 결과는 Table 1의 7-10줄에 나와 있습니다. 이러한 설정을 사용하여, VGG16과 VGGM의 mAP는 B = 128과 비교하여 약 1 점 증가했지만, 우리 접근법의 개선은 여전히 모든 RoI를 사용하는 것보다 1 점 이상입니다. 또한, 더 작은 미니배치 크기로 그래디언트를 계산하기 때문에 학습 속도가 더 빨라집니다.
5.5 Better optimization
마지막으로, 우리는 위에서 논의한 다양한 FRCN 학습 방법에 대한 학습 손실(training loss)을 분석합니다. 샘플링 절차에 의존하지 않고 training loss를 측정하는 것은 중요합니다. 이를 위해 최적화 단계마다 각 방법에서 모델 스냅샷을 20k 단위로 취하고, 이들을 전체 VOC07 trainval 세트에서 실행하여 모든 RoI의 평균 손실을 계산합니다. 이는 예제 샘플링 방식에 의존하지 않고 학습 세트 손실을 측정하는 방법입니다.
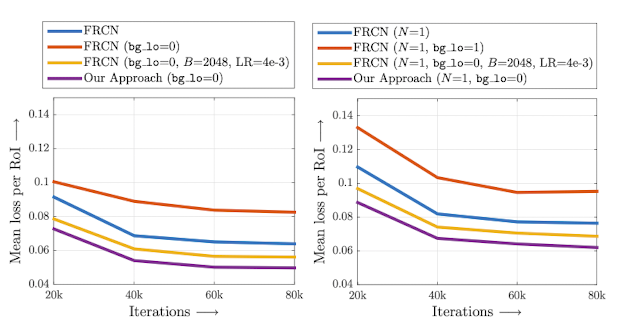
Figure 3는 위에서 언급하고 Table 1에서 제시된 VGG16의 다양한 하이퍼파라미터 설정에 대한 RoI당 평균 손실을 보여줍니다. bg lo = 0을 사용하면 가장 높은 훈련 손실이 발생하는 반면, 휴리스틱인 bg lo = 0.1을 사용하면 훨씬 낮은 훈련 손실이 발생합니다. 미니배치 크기를 B = 2048로 늘리고 학습률을 높이면 훈련 손실이 bg lo = 0.1 휴리스틱 아래로 내려갑니다. 우리가 제안한 OHEM 방법은 모든 방법 중에서 가장 낮은 train loss를 달성하여, OHEM이 FRCN의 더 나은 훈련을 이끌어 낸다는 주장을 검증합니다.
5.6 Computational cost
OHEM은 VGGM 네트워크에 대해 학습 반복당 0.09초 (VGG16에 대해서는 0.43초)가 소요되며 1G의 추가 메모리가 필요합니다 (VGG16에 대해서는 2.3G).


참고 자료/이미지 출처
'Computer Vision' 카테고리의 다른 글
CLIP: Contrastive Language-Image Pre-training 논문 핵심 요약 (0) 2024.03.04 R-CNN 논문 읽기 (0) 2023.03.14 Yolov7 커스텀 데이터셋에 학습시키기 (2) 2023.03.07 OverFeat 논문 요약 (1) 2023.03.06 You Only Look Once (YOLO) 논문 요약 (0) 2023.02.22