-
OverFeat 논문 요약Computer Vision 2023. 3. 6. 11:55
https://arxiv.org/pdf/1312.6229.pdf
목차
0. Abstract
3. Classification
4. Localization
5. Detection
Abstract
1. Convolution Network를 사용하여 Classification, Localization, Detection을 수행하는 통합된 framework를 소개
2. ConvNet에서 multiscale과 sliding window 기법이 효율적으로 구현될 수 있는지를 보임
3. Object boundary를 예측하는 것을 학습하는 방법을 통한 새로운 localization 기법을 소개함
4. 하나의 공유된 네트워크로 다른 task들을 동시에 학습할 수 있는 방법을 보임. 통합된 프레임워크는 2013년 ILSVRC localization task의 우승자이며 detection과 classification task에서도 좋은 성적을 냄.
5. OverFeat라는 feature extractor를 공개
3. Classification
본 논문의 classification 아키텍쳐는 AlexNet 아키텍쳐()와 비슷합니다. 다만 이를 그대로 사용하지 않고 네트워크 디자인과 추론 단계를 향상시켰다고 합니다.

AlexNet의 아키텍처 3.1. Model Design and Training
네트워크는 ImageNet 2012 학습 데이터셋 (120만개의 이미지 및 1000개의 클래스)으로 학습되었습니다. 학습 중에는 Krizhevsky 등이 제안한 고정 입력 크기 (fixed input size) 접근 방식을 사용하지만, 분류에서는 다중 스케일을 사용합니다.
각 이미지는 가장 작은 차원이 256 픽셀이 되도록 다운샘플링됩니다. 그다음 221x221 크기의 5개 무작위 subsample (및 해당하는 수평 방향 반전)을 추출하고 이를 128 크기의 미니배치에 제공합니다.
네트워크의 가중치는 (μ, σ) = (0, 1 × 10−2)로 무작위로 초기화되며, 이후에는 모멘텀 항이 0.6이고 l2 가중치 감쇠가 1 × 10^(−5)인 SGD로 업데이트됩니다. 학습률은 처음에는 5 × 10^(−2)이며 (30, 50, 60, 70, 80) epoch 이후에 0.5의 비율로 계속 감소됩니다. Classifier의 fully connected layer (6번째와 7번째)에서 DropOut을 사용하며, 이의 비율은 0.5입니다.
- 네트워크 가중치 초기화 : (μ, σ) = (0, 1 × 10−2)
- 모멘텀 항 0.6, l2 weight loss 1 × 10^(−5)인 SGD로 업데이트
- learning rate은 처음에는 5 × 10^(−2)이며 (30, 50, 60, 70, 80) epoch 이후에 0.5의 비율로 계속 감소
- Classifier의 fully connected layer (6번째와 7번째)에서 DropOut을 사용, 비율은 0.5
아키텍쳐 사이즈는 다음의 표에 나와있습니다.
학습시에는 아키텍쳐를 non-spatial으로 취급하지만, 추론 시에는 spatial ouput을 출력한다고 합니다.
"non-spatial" 아키텍처라는 용어는 입력 데이터의 특징들 사이의 공간적 관계를 명시적으로 고려하지 않는 네트워크 아키텍처의 유형을 의미합니다. 즉, 이러한 아키텍처들은 이미지에서 픽셀들의 상대적 위치나 시퀀스에서 특징들의 시간적 순서와 같은 입력 데이터의 공간 구조를 보존하지 않습니다.공간이 없는 아키텍처의 예로는 fully connected layer (dense networks)와 연결에 명시적인 공간 또는 시간적 구조가 없는 특정 유형의 RNN이 있습니다. 대조적으로, CNN과 LSTM 네트워크와 같은 일부 유형의 RNN은 입력 데이터의 공간 또는 시간 구조를 캡처하도록 설계되어 있으므로 "spatial" 또는 "temporal" 아키텍처라고 합니다.
학습시에는 아키텍처를 non-spatial으로 취급하지만, 추론 시에는 spatial ouput을 출력한다고 하는 것은, 학습시에는 네트워크가 1x1 디멘션의 output map을 출력하지만, 추론시에는 output map이 이보다 큰 디멘션을 갖는다는 것을 의미합니다.FC 레이어를 마지막 레이어로 갖는 경우, 고정된 출력값을 갖지만, 이를 convolution layer로 바꾸면, 인풋 사이즈에 대해 다른 크기의 아웃풋 맵을 출력하는 네트워크가 됩니다.
본 논문에서는 3.5 절에 나와있는 것처럼, FC 레이어를 테스트 시간에 1x1 크기를 갖는 convolution layer로 대체하므로, non spatial 아키텍쳐가 spatial 아키텍쳐로 바뀌게 됩니다.1~5 레이어의 경우에는 AlexNet과 거의 동일합니다. 다른점은 첫 번째, contrast normalization이 사용되지 않으며, 두 번째, pooling region들이 겹치지 않는다는 점이며, 세 번째, 더 작은 stride를 사용하여 1, 2번째 피쳐맵이 더 크다는 점입니다. 큰 stride를 사용하는 경우 정확도에 좋지 않은 영향을 준다고 합니다.
AlexNet이 소개된 논문인 [Image classification with deep convolutional neural networks]에서는 정확도를 높이기 위한 방법중 하나로 pooling에 중복을 허용하는 Overlapping pooling을 사용하고 있습니다.
3.2. Feature Extractor
저자들은 또한 Feature Extractor인 OverFeat를 소개합니다. OverFeat는 두 가지 버전, fast, accurate 이 있습니다. accurate 모델의 경우에는 fast 모델보다 정확하지만(14.18%과 16.39%), connection이 두 배 가까이 필요하다고 합니다.
3.3. Multi-Scale Classification
AlexNet에서는 성능을 향상시키기 위해 multi-view voting을 사용합니다. Multi-view voting에서는 고정된 10개의 시점(4개의 코너, 중앙 그리고 이를 수평 방향으로 뒤집은 시점)이 평균화됩니다.
그러나 이 방법은 이미지의 많은 영역을 무시할 수 있으며, 뷰가 중복될 때 계산 또한 중복됩니다. 또한 하나의 스케일에서만 적용되므로 ConvNet이 최적으로 응답할 수 있는 스케일이 아닐 가능성이 있습니다.
대신에, 본 논문에서는 슬라이딩 윈도우 방식을 사용합니다. 슬라이딩 윈도우 방식은 다른 모델의 계산에 대해서는 비효율적일 수 있지만 ConvNet의 경우에는 효율적입니다. 이 접근법은 voting을 위한 더 많은 뷰를 생성하므로 효율성을 유지하면서 견고성을 증가시킵니다. 임의의 크기의 이미지에 대한 ConvNet 합성곱의 결과는 각 스케일마다 C차원 벡터의 공간 맵입니다.
그러나 위에서 설명한 네트워크에서의 총 subsampling 비율은 2x3x2x3 = 36이므로 밀도있게 적용될 때 이 아키텍처는 각 축의 입력 차원에서 36 픽셀마다 하나의 분류 벡터만 생성할 수 있습니다. 출력의 이러한 거친 (coarse) 분포는 네트워크 창이 이미지의 객체와 정렬되어 있지 않기 때문에 10-view 방식과 비교하여 성능을 감소시킵니다.
총 감소 비율은 stride를 통해 이미지가 축소되는 전체 값을 의미합니다. 따라서 아래의 표에서 하이라이트로 표시된 부분에 해당합니다.

이는 다음과 같이 하나의 칸이 인풋 이미지의 36개의 픽셀값을 담고 있다는 의미가 됩니다.
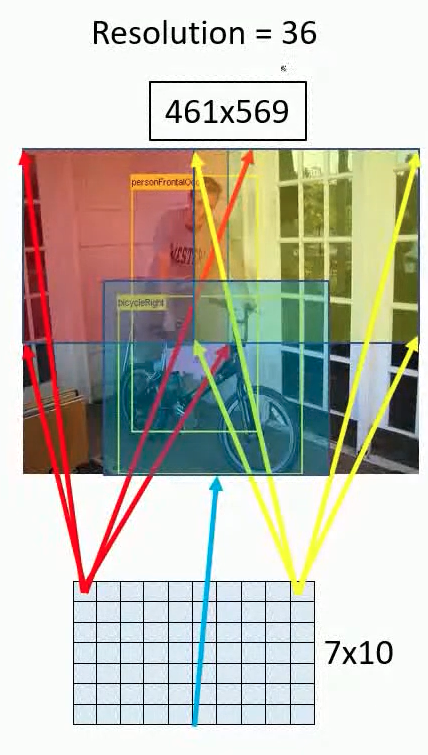
이미지 출처: https://www.youtube.com/watch?v=t5PHp8uSMKo&list=PL1GQaVhO4f_jLxOokW7CS5kY_J1t1T17S&index=55 이 문제를 해결하기 위해, 저자들은 Giusti 등이 도입한 방법과 유사한 접근법을 취하여 마지막 subsampling을 각 오프셋에서 적용하였다고 합니다. 이렇게 하면 이 레이어에서 해상도 손실이 제거되어 총 감소 비율이 x36이 아닌 x12가 됩니다.
이제 이러한 resolution augmentation이 어떻게 수행되는지 자세히 설명하겠습니다.
우선, 6개의 각기 다른 입력 스케일을 사용하여 다양한 resolution을 갖는 pooling 되지 않은 layer 5의 map들을 추출합니다. (밑의 표에서 Layer 5 pre-pool) 그 다음에 이들을 pooling하고 Fig 3에 나와있는 것처럼 classifier를 통과시킵니다.

Table 5 
Fig 3 (a) 주어진 이미지에 대해서 unpooled layer 5 피쳐맵부터 시작합니다.
(b) 각각의 unpooled map들은 3x3 pooling operation을 통과합니다. 이는 x, y축에 대해 그리고 pixel offset {0,1,2}에 대해 3*3번 반복됩니다.
(c) 이러한 과정은 pooling된 피쳐맵들의 집합을 생성합니다.
(d) Classifier (layers 6,7,8)의 경우에는 고정된 인풋 크기(5x5)를 요구하고 피쳐맵의 각각의 위치에서 C-dimensional output vector를 생성합니다. 따라서 풀링맵에 sliding window 방식으로 classifier가 적용되어 출력 맵을 생성합니다.
위의 그림을 통해 보면 1차원으로 표시된 맵 1*6 차원의 맵이 1*5 classifier를 통과하여 1*2차원이 되는 것을 볼 수 있습니다.

(e) 다른 축들(x, y)을 위한 각각의 output map들은 하나의 3D output map으로 재형성됩니다.
3.4 Results
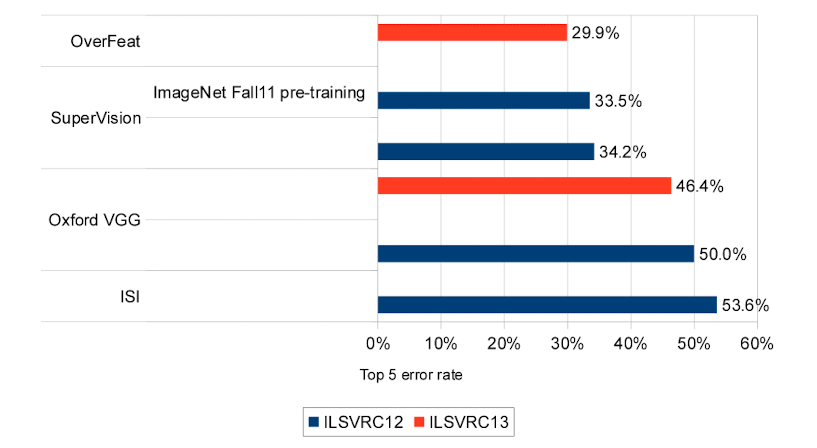
다음의 표는 다른 방식들과 Krizhevsky가 제안한 하나의 네트워크를 비교한 값을 보여줍니다. 위에서 설명된 방식은 top-5 error rate 13.6%를 달성합니다.


3.5 ConvNets and Sliding Window Efficiency
다른 많은 sliding window 접근방식과 달리, ConvNet은 중복되는 영역에서 computation을 공유하기 때문에 비교적 효율적이라고 볼 수 있습니다. 테스트시에 더 큰 이미지를 적용하는 경우, 단순하게 확장된 부분에만 convolution을 적용하면 됩니다.

아키텍처의 마지막 계층은 fully connected linear 계층입니다. 테스트 시에 이러한 레이어는 1x1 spatial 범위의 커널을 가진 컨볼루션 연산으로 대체됩니다. 그러면 전체 ConvNet은 컨볼루션, 풀링 및 thresholding 처리의 시퀀스가 됩니다.
4. Localization
분류를 수행하도록 훈련된 네트워크에서 시작하여, 네트워크의 classifier layer을 regression 네트워크로 대체하고 각 공간 위치와 scale에 대해서 object bounding box를 예측하도록 훈련됩니다. 그런 다음 각 위치에 대해서 분류 결과와 함께 회귀 예측을 결합합니다.
4.1 Generating Predictions
물체의 bounding box 예측을 생성하기 위해 모든 위치와 규모에서 classifier 및 regressor 네트워크를 동시에 실행합니다. 이들은 동일한 feature extraction 계층을 공유하기 때문에 classification 네트워크를 계산한 후 최종 regression 계층만 다시 계산하면 됩니다. 각 위치에서 클래스 c에 대한 최종 소프트맥스 레이어의 출력은 클래스 c의 객체가 해당 시야에 (반드시 완전히 포함되지는 않지만) 존재한다는 confidence score를 제공합니다.
이미지의 빈공간에 대해 네트워크가 classification을 수행하는 경우가 있으므로 confidence score를 통해 잘못된 분류를 제거합니다.

이미지 출처: https://www.youtube.com/watch?v=t5PHp8uSMKo&list=PL1GQaVhO4f_jLxOokW7CS5kY_J1t1T17S&index=55 4.2 Regressor Training
Regression 네트워크는 Layer 5의 pooling된 feature map을 인풋으로 받습니다. 네트워크는 각각 4096과 1024 채널 사이즈를 갖는 두 개의 fully-connected hidden layer를 갖고 있습니다. 최종 출력 레이어는 bounding box의 꼭짓점의 좌표를 나타내는 4개의 unit을 가지고 있습니다. Classification의 경우에는 offset shift로 이한 (3*3)개의 복사본이 있습니다.
분류 네트워크의 feature extraction 레이어 (1-5)를 고정하고 각각의 예제에 대해 예측된 bounding box와 실제 bounding box 사이의 l2 loss를 사용하여 regression 네트워크를 훈련합니다. 마지막 regressor 레이어는 클래스별로 다르며 1000 가지 버전이 있습니다. 이 네트워크를 섹션 3에서 설명한 다양한 스케일의 집합을 사용하여 훈련합니다. 각 공간 위치에서 regressor 네트워크의 예측과 regressor translation 오프셋의 참조 프레임으로 이동된 ground truth bounding box를 비교합니다.
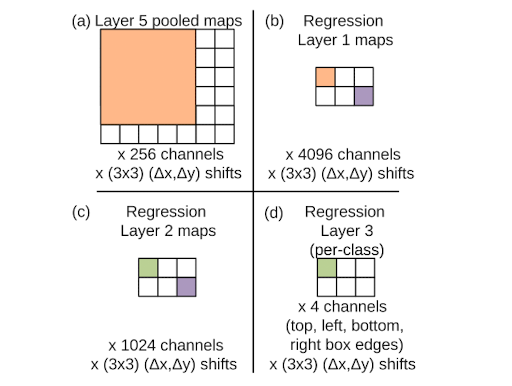
위의 그림은 2번째 scale(281x317)의 이미지를 regression layer 5의 feature에 적용한 예시입니다.
(a) 이 크기에서 regressor의 입력은 각각 ∆x, ∆y의 이동(3x3)에 대해 6x7 픽셀 공간적으로 256 채널입니다.
(b) regression 네트워크의 1번째 레이어의 각 유닛은 5x5 공간과 레이어 5 맵의 모든 256 채널에 연결됩니다. 5x5 칸을 이동하면 레이어의 4096 채널 각각에 대해 2x3 공간 범위의 맵이 생성됩니다.
(c) 2번째 regression 레이어는 1024 개의 유닛을 가지며 완전 연결됩니다 (즉, 보라색 요소는 모든 4096 채널에서 (b)의 보라색 요소에만 연결됩니다).
(d) 회귀 네트워크의 출력은 2x3 맵의 각 위치 및 ∆x, ∆y 이동(3x3)의 각각에 대해 바운딩 박스의 가장자리를 지정하는 4-벡터입니다.Table 5 4.3 Combining Predictions
각각의 regressor bounding prediction을 그리디 머지 strategy를 적용하여 통합합니다.


위에 나온 match_score의 경우에는 두 개의 bounding box의 중심 거리와 box의 intersection area를 더하는 것으로 계산합니다.
box_merge의 경우에는 Bounding box 좌표의 평균을 계산합니다.
최종 예측은 최대 클래스 점수를 가진 병합된 bounding box를 선택함으로서 제공됩니다. 이는 각 bounding box 예측된 입력 창과 관련된 탐지 클래스 출력을 누적으로 추가하여 계산됩니다.

위의 그림을 보면, 여러개의 bounding box가 하나의 높은 신뢰도를 갖는 box로 합쳐진 것을 볼 수 있습니다.
이 예에서 일부 거북이 및 고래의 bounding box는 중간 단계에서는 나타나지만 최종 detection image에서는 사라집니다. 이러한 bounding box는 분류 신뢰도가 낮을 뿐만 아니라, 곰의 경계 상자만큼의 일관성이 없습니다. 곰 상자는 신뢰도가 높고 일치하는 점수가 높습니다. 따라서 병합 후 많은 곰 경계 상자가 단일 매우 높은 신뢰 box로 융합되는 반면, false positive는 bounding box 일관성과 신뢰성 부족으로 인해 detection threshold 아래로 사라집니다. 이는 위에서 설명한 접근 방식이 bounding box 일관성을 보상함으로써 기존의 NMS보다 순수 분류 모델에서 발생하는 false positive에 더 강력하다는 것을 시사합니다.
4.4 Experiments
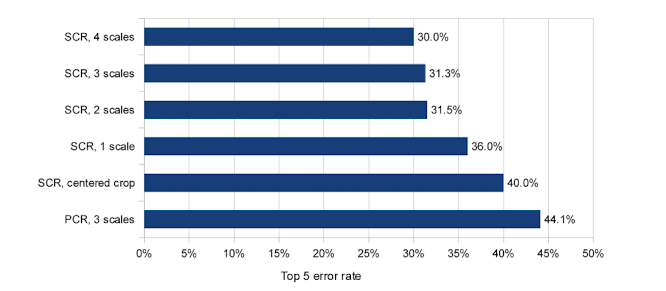
SCR: single class regression
PCR: per-class regression
5. Detection
Detection 학습은 classification 학습과 유사하지만 하나의 이미지 내 여러 위치가 동시에 학습될 수 있으므로 공간적인 방식으로 이루어집니다. 또한, 모델이 합성곱적(convolutional)이기 때문에 모든 가중치는 모든 위치에서 공유됩니다.
Localization 작업과의 주요한 차이점은 물체가 존재하지 않을 때의 배경 클래스를 예측해야 한다는 것입니다. 전통적으로, negative 예제들은 무작위로 선택된 후에 부트스트랩(bootstrapping) 패스에서 가장 문제가 되는 negative error가 학습 세트에 추가됩니다.
독립적인 부트스트랩 패스는 학습을 복잡하게 하고 negative 예제 수집과 학습 시간 간의 불일치 문제가 발생할 수 있습니다. 또한, 부트스트랩 패스의 크기는 작은 데이터셋에서 overfitting 되지 않도록 조절되어야 합니다.
이러한 문제들을 해결하기 위해, 저자들은 이미지 당 몇 개의 흥미로운 negative 예제(무작위 또는 가장 문제가 되는 예제)를 선택하여 온라인으로 부정적인 학습을 수행했습니다. 이 방법은 계산 비용이 더 많이 들지만 절차를 훨씬 단순화시킨다고 합니다.


이미지 출처 및 참고
https://www.youtube.com/watch?v=t5PHp8uSMKo&list=PL1GQaVhO4f_jLxOokW7CS5kY_J1t1T17S&index=55
'Computer Vision' 카테고리의 다른 글
OHEM 논문 읽기 (0) 2023.03.08 Yolov7 커스텀 데이터셋에 학습시키기 (2) 2023.03.07 You Only Look Once (YOLO) 논문 요약 (0) 2023.02.22 Ground-aware Monocular 3D Object Detection for Autonomous Driving 논문 공부 (0) 2022.08.05 [openCV] YOLO object detection (video) (0) 2022.07.30
