-
MonoDTR: Monocular 3D Object Detection with Depth-Aware Transformer 논문 공부Computer Vision 2022. 7. 12. 11:28
시작하기 전에
1. Transformer란?
Transformer는 구글이 2017년에 발표한 논문인 “Attention is all you need"에서 나온 모델로 기존의 seq2seq의 구조를 따르지만 내부적으로 RNN 레이어 없이 어텐션으로만 구현한 모델이다.
2. seq2seq와 Attention이란?
sequence-to-sequence 모델은 말 그대로, 아이템(예를 들어 사진) 시퀀스를 인풋으로 받고 또다른 아이템 시퀀스를 아웃풋으로 출력하는 모델이다.

seq2seq 모델은 내부적으로 인코더와 디코더로 이루어져있다.
인코더는 input sequence를 받아 각각의 아이템을 처리하고 알아낸 정보를 벡터(context)로 바꾼다. 모든 아이템에 대해 처리를 마친 후에 이를 디코더에 보낸다. 인코더와 디코더는 주로 둘다 하나의 RNN이다. 따라서 인코더와 디코더는 각각 처리를 수행할 때 마다 인풋과 전의 인풋에 따라 hidden state를 업데이트 한다. 인코더와 디코더가 수행하는 작업을 간단하게 나타내면 다음과 같다.
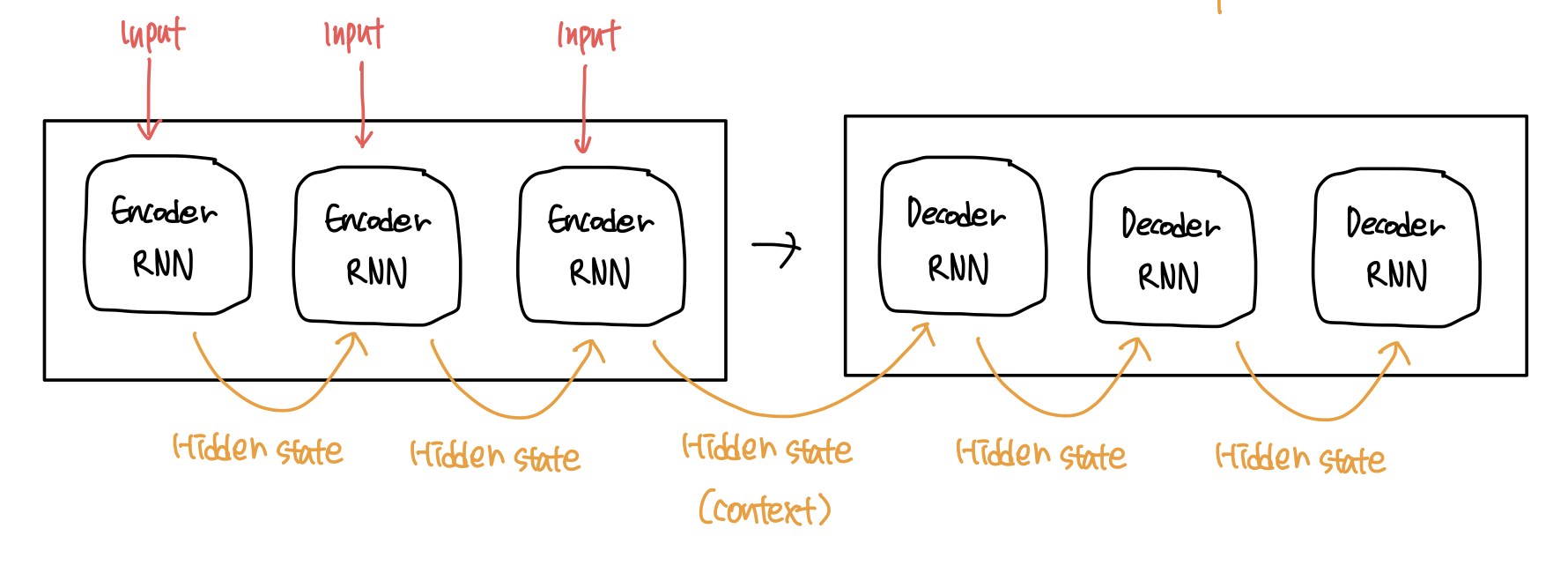
이러한 종류의 모델에 있어서 context vector가 병목 현상을 일으키는 것으로 밝혀졌다. 하나의 context 벡터가 소스 문장의 모든 정보를 가지고 있어야 하므로 모든 state의 정보를 하나의 벡터에 담으려하다보니 성능이 저하될 수 있는 것이다. 그렇다면 매번 소스 문장에서 출력 전부를 입력을 받으면 문제가 해결되지 않을까?
따라서 이에 대한 해결책으로 “Attention”이라는 기술이 나왔다.
Attention의 기본 아이디어는 디코더에서 출력을 예측하는 매 시점마다 (time step) 인코더에서의 전체 입력을 다시 한 번 참고한다는 점이다. 단, 전체 입력을 전부 다 동일한 비율로 참고하는 것이 아니라, 해당 시점에서 예측해야할 단어와 연관이 있는 입력 단어 부분에 좀 더 집중(Attention)해서 보게 된다.
Attention 모델은 기존의 seq2seq 모델과 두 가지의 큰 면에서 차이가 있다.
첫번째로 인코더가 디코더에 context를 전달할 때, 기존의 seq2seq 모델이 hidden state를 한 개만 전달했던 것과 달리 모든 hidden state를 디코더에 전달한다.
두번째로 attention 디코더는 아웃풋을 만들기 전에 다음과 같은 추가적인 단계를 수행한다.
- 인코더에서 보낸 hidden state의 셋을 보고 각각의 hidden state에 대해 스코어를 매긴다.
- 각각의 hidden state에 대해 그들의 softmax를 거친 스코어 값을 곱한다. 따라서 스코어가 높은 hidden state는 커지고, 스코어가 낮은 hidden state는 작아지게 된다.
- 이렇게 계산된 hidden state를 모두 더한 값이 하나의 step에 대한 context 벡터가 된다.
다시 Transformer에 대한 이야기로 돌아와서, 앞서 말했듯이 transformer는 기존의 seq2seq 모델과 동일한 인코더, 디코더 구조로 이루어져있지만, 내부적으로 RNN 레이어 없이 Attention으로만 이루어진 모델이다. 트랜스포머는 RNN이나 CNN을 전혀 사용하지 않고 Attention 과정을 여러 레이어에서 반복한다. 또한 순서에 대한 정보를 주기 위해 Positional Encoding을 사용한다.

encoding component는 인코더들의 스택으로 이루어져있고 decoding component는 똑같은 수의 디코더 스택으로 이루어져있다. 이때 인코더들은 모두 동일한 구조를 가지며 각각은 두 개의 서브레이어로 나뉠 수 있다. 인코더의 입력은 일단 self-attention 레이어를 거치며 여기서 나온 아웃풋은 다시 feed-forward neural network로 들어간다.

디코더는 인코더와 똑같은 두 가지의 레이어를 가지지만 두 개의 레이어 사이에 Encoder-decoder attention 레이어를 추가로 갖는다. encoder-decoder attention 레이어는 인코더의 가장 마지막 레이어에서 나오게 된 출력 값을 받아 input sequence에서 관계 있는 부분에 집중할 수 있도록 해준다. 따라서 인코더의 가장 마지막 레이어에서 나온 출력 값은 디코더의 모든 레이어에 입력 값으로 들어가게 된다.
Self attention은 내부적으로 다음과 같이 이루어진다.
쿼리(Query): 물어보는 주체
키(Key): 물어보는 대상
값(Value):
예를 들어 "I am a teacher"라는 문장이 있을 때 I라는 단어가 다른 단어와 얼마나 연관성을 갖는지 측정하기 위해서 self-attention을 수행할 수 있는데, 여기서 쿼리는 'I'가 되는 것이고 'I' 'am' 'a' 'teacher'는 키가 된다. 스코어를 구하고 난 후에는 Value 값들과 곱해서 Attention value 값을 구할 수 있다.

3. Object Detection: Backbone, Head 란?
object detection은 컴퓨터 비전과 이미지 처리와 관련된 컴퓨터 기술로, 디지털 이미지와 비디오로 특정한 계열의 시맨틱 객체 인스턴스(예: 인간, 건물, 자동차)를 감지하는 일을 다룬다. object detection을 위한 방식은 일반적으로 기계학습 기반 접근 또는 딥러닝 기반 접근으로 분류된다. 기계 학습 접근의 경우 우선 아래의 방식들 가운데 하나를 사용하여 정의한 다음 서포트벡터머신(SVM) 등의 기법을 사용하여 분류하는 일이 필요하다. 한편, 딥러닝 기법은 기능을 구체적으로 정의하지 않고서도 단대단 객체 탐지를 할 수 있으며 CNN에 기반을 두는 것이 보통이다.
- 딥러닝 접근:
- Region Proposals (R-CNN, Fast R-CNN, Faster R-CNN, cascade R-CNN)
- Single Shot MultiBox Detector (SSD)
- You Only Look Once (YOLO)
- Single-Shot Refinement Neural Network for Object Detection (RefineDet)
- Retina-Net
- Deformable convolutional networks
나무위키 - object detection (https://ko.wikipedia.org/wiki/객체_탐지)

출처: https://velog.io/@hewas1230/ObjectDetection-Architecture Backbone: 딥러닝 모델에서 upper layers에 해당하는 pre-trained network. feature map을 생성하는 파트
Head: classification이나 regression 같은 '검출'이 이루어지는 실질적인 부분.
논문 리뷰
Abstract
논문의 저자는 기존에 monocular 3D detection을 위한 방식에서의 computational burden과 제한된 성능을 개선하기 위해 MonoDTR을 소개한다. MonoDTR은 end-to-end depth aware transformer network로, Depth-aware feature enhancement (DFE) module, Depth-aware transformer (DTR) module 두 가지 구성요소로 이루어져있다. DFE는 추가적인 계산 비용 없이 보조적인 supervision을 통해 depth-aware feature를 학습하고 DTR module은 context, depth aware feature를 전체적으로 통합한다. 또한 기존의 pixel-wise positional encoding 방식과는 다른, 새로운 depth positional encoding (DPE)을 통하여 transformer에 depth positional hint를 주입하는 방식을 소개한다.
1. Introduction
기존에 3D object detection을 위해 사용되었던 방식들은 다음과 같다.
- LiDAR signal 과 같은 Multiple sensor를 통한 Depth information
- Stereo matching
- Image only 3D object detection method - Geometry constraints between 2D and 3D
하지만 이러한 방식은 depth cues의 도움없이는 만족스러운 성능을 얻지 못한다고 한다.
Pre-trained depth estimation models을 사용하는 monocular 3D object detection은 다음과 같은 것들이 있을 수 있다.
- Pseudo-LiDAR-based methods
- Fusion-based methods
위의 두 가지 방식을 사용하여 depth를 추정하는 방법들은 추정된 깊이 정보를 통해 object를 더 잘 localize 할 수 있다는 장점이 있지만 부정확한 depths map을 통해 3D detection을 학습할 수 있다는 단점이 있다. 따라서 저자는 위와 같은 문제를 해결하기 위한 방법으로 monocular 3D object Detection을 위한 새로운 end-to-end depth aware transformer network를 소개한다.
monoDTR에는 보조적인 depth supervision을 통해 depth-aware feature를 학습하는데 DFE 모듈이 사용되고 이러한 방식은 pretrained depth estimator에서 부정확한 depth prior를 얻는 것을 방지한다고 한다.
또한 복잡한 아키텍처를 구성하지 않고도 3D object detection을 지원하기 때문에 가볍고 효과적이고 계산 시간을 크게 단축할 수 있다고 한다.
거기에 더해 transformer-based fusion module을 통해 이미지와 깊이 정보를 전역적으로 통합하고 long range dependency를 캡쳐하는데 효과적인 transformer의 encoder, decoder 구조를 context와 depth aware feature의 관계를 모델하는데 사용한다.
2. Related Work
Image-only monocular 3D object detection
이미지만을 사용하는 monocular 3D object detection은 object를 예측하는데 주로 기하학적인 정합성에 의존한다. 이를 사용한 몇몇 연구들에 대한 문제로 저자는 depth cue의 부족으로 정확하게 object를 localize하지 못한다는 점을 지적했다.
Depth-assisted monocular 3D object detection
성능을 개선하기 위한 방법으로 많이 쓰이는 방법이 깊이 정보를 보조적으로 사용하여 3D object detection을 수행하는 것이다.
몇몇 연구는 이를 위해 기존의 depth estimator와 calibration parameter를 사용하여 image를 pesudo-LiDAR로 나타내고 기존 LiDAR 기반 3D detector를 사용하여 object를 예측한다. 이러한 방식은 성능을 개선하지만, 추가적인 계산 비용 문제를 겪고 부정확한 depth prior로 인한 제한된 성능을 달성한다.
Transformer
Image-based 3D detection 작업에서, 이미지에서 원거리와 근거리에서의 object 크기는 perspective projection으로 인해 크게 달라지기 때문에 선행 연구인 DETR에서 언급된 학습된 object 쿼리를 활용하여 object property를 완전히 표현하기가 어렵다고 한다. 따라서 저자는 더 나은 3D reasoning을 위해 depth-aware feature를 transformer와 전역적으로 통합하고 깊이 힌트를 Transformer에 주입할 것을 제안한다.
3. Proposed Approach
3.1 Framwork Overview
MonoDTR은 크게 네 가지의 구성요소로 이루어져있다.
- Backbone
- DFE (depth-aware feature enhancement)
- DTR (depth-aware transformer)
- 2D-3D Anchor definition detection head

우선, 해상도 H_inp X W_inp 의 RGB 이미지가 인풋으로 주어지면, backbone은 Feature map을 아웃풋으로 출력한다. DFE 모듈은 Auxiliary depth supervision을 통해 depth aware feature를 학습하고 여러개의 convolution layer는 병렬의 context-aware feature를 추출한다. 그런 다음에 DTR 모듈을 통해 두 종류의 feature를 통합하고 DPE 모듈을 통해 트랜스포머에서 depth positional hint를 주입한다. 마지막으로 anchor-based detection head와 loss function을 통해 2D, 3D obejct detection을 수행한다.
3.2 Depth-Aware Feature Enhancement Module (DFE)
Learning initial depth-aware feature
depth-aware feature을 생성하기 위해 보조적인 깊이 추정 작업을 활용하고 sequential classification 문제로 간주한다.
백본에서 input feature F가 주어지면, 이산화된 depth bin D의 확률을 예측하기 위해 두 개의 컨볼루션 레이어를 사용한다.
또한 연속 공간에서 이산화 간격까지 depth ground truth를 이산화하기 위해 Linear-increasing discretization(LID)를 활용하여 깊이 빈을 수식화한다.
Depth prototype representation learning
깊이 표현 feature을 더욱 강화하기 위해 central representation of the corresponding depth category를 도입하여 각 픽셀의 feature을 강화한다. 각 깊이 범주의 feature center은 지정된 범주에 속하는 각 픽셀의 depth-aware feature을 종합하여 계산할 수 있다.
Feature enhancement with depth prototype
depth prototype representation을 통해 새로운 depth-aware feature를 reconstruct할 수 있고 이를 통해 얻은 F'와 initial depth-aware feature X를 이어붙임으로써 enhanced depth feature를 얻을 수 있다.
3.3 Depth-Aware Transformer
Transformer encoder
MonoDTR의 Transformer encoder는 이전의 연구에서와 비슷하게 context-aware feature를 향상시키는 것이 목표이다.
Transformer decoder
Decoder 또한 표준 Transformer achitecture와 동일하지만 다른 점은 learnable 임베딩(object query) 대신 depth-aware feature을 디코더의 입력으로 활용한다는 점이다. 저자는 depth-aware feature를 사용하는 이유가 perspective projection으로 인해 camera view가 가까울 때와 멀때 object scaler이 굉장히 크게 바뀔 수 있다는 점이라고 설명했다.
Depth positional encoding (DPE)
앞서 트랜스포머에 대해 설명할 때 트랜스포머가 RNN, CNN을 사용하지 않기 때문에 positional encoding을 사용하여 위치 정보를 주입한다고 설명한 바가 있다. 저자는 이러한 positional encoding을 수행하는 데에 깊이 정보가 pixel level relationship보다 3D 월드를 기계가 이해하는 데에 더 낫다는 것을 바탕으로 depth positional encoding을 제안한다. DPE는 각각의 픽셀에 대해 depth positional hint를 주입한다.

Computation reduction
MonoDTR에서는 계산 비용을 줄이기 위해 vanilla self-attention 대신에 linear attention을 적용한다.
참고 자료
http://jalammar.github.io/illustrated-transformer/
The Illustrated Transformer
Discussions: Hacker News (65 points, 4 comments), Reddit r/MachineLearning (29 points, 3 comments) Translations: Chinese (Simplified), French 1, French 2, Japanese, Korean, Russian, Spanish, Vietnamese Watch: MIT’s Deep Learning State of the Art lecture
jalammar.github.io
Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)
Translations: Chinese (Simplified), French, Japanese, Korean, Persian, Russian, Turkish Watch: MIT’s Deep Learning State of the Art lecture referencing this post May 25th update: New graphics (RNN animation, word embedding graph), color coding, elaborate
jalammar.github.io
https://www.youtube.com/watch?v=UNmqTiOnRfg
https://www.youtube.com/watch?v=AA621UofTUA
https://velog.io/@hewas1230/ObjectDetection-Architecture
Object Detection : Backbone, Neck and Head Architecture
※YOLOv4 논문의 2. Related Work 파트를 참고하였습니다.안녕하세요, :) 입니다.이번 포스트는 아마 제가 입대하기 전 마지막 포스트가 될 것 같은데요,Object detection이 ML이나 DL과는 완전히 다른 영역
velog.io
https://ko.wikipedia.org/wiki/객체_탐지
객체 탐지 - 위키백과, 우리 모두의 백과사전
ko.wikipedia.org
'Computer Vision' 카테고리의 다른 글
OverFeat 논문 요약 (1) 2023.03.06 You Only Look Once (YOLO) 논문 요약 (0) 2023.02.22 Ground-aware Monocular 3D Object Detection for Autonomous Driving 논문 공부 (0) 2022.08.05 [openCV] YOLO object detection (video) (0) 2022.07.30 [openCV] Object height 알아내기(python) (0) 2022.07.25