-
핸즈온 머신러닝[6] 결정 트리핸즈온머신러닝 2022. 7. 6. 15:36
https://www.youtube.com/watch?v=h9PRMril20M&list=PLJN246lAkhQjX3LOdLVnfdFaCbGouEBeb&index=19
결정 트리 학습과 시각화
from sklearn.datasets import load_iris from sklearn.tree import DecisionTreeClassifier iris = load_iris() X = iris.data[:, 2:] # 꽃잎 길이와 너비 y = iris.target tree_clf = DecisionTreeClassifier(max_depth=2, random_state=42) tree_clf.fit(X, y)붓꽃 데이터셋에 DecisionClassifier를 훈련시키는 코드
from graphviz import Source from sklearn.tree import export_graphviz export_graphviz( tree_clf, out_file=os.path.join(IMAGES_PATH, "iris_tree.dot"), feature_names=iris.feature_names[2:], class_names=iris.target_names, rounded=True, filled=True ) Source.from_file(os.path.join(IMAGES_PATH, "iris_tree.dot"))export_graphviz() 함수를 통해 그래프 정의를 iris_tree.dot 파일로 출력하여 훈련된 결정 트리를 시각화할 수 있다.
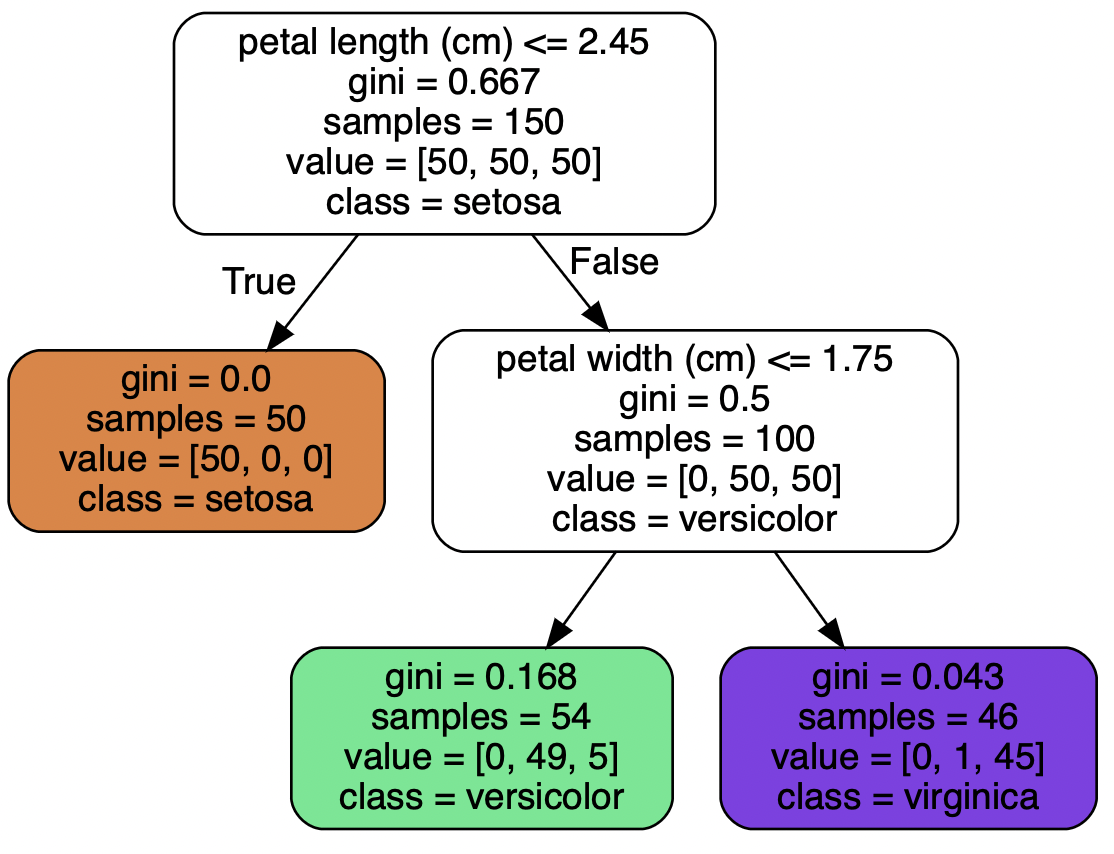
from sklearn.tree import plot_tree plot_tree(tree_clf, filled=true, rounded=true, feature_names=iris.feature_names[2:], class_names=iris.target_names) plt.show()사이킷런의 plot_tree를 통해서도 위와 똑같은 그림을 그릴 수 있다. 또한 max_depth 파라미터를 통해 특정 깊이까지만 출력할 수 있다는 장점이 있다.
예측하기
트리가 예측을 하기 위해서는 우선 루트 노드에서 시작한다. 해당 노드는 꽃잎 길이를 검사해서 2.45cm보다 긴지 짧은지 검사한다.
만약 꽃잎이 2.45cm보다 짧다면 왼쪽 노드로 이동한다. 왼쪽 노드는 리프 노드이므로 검사를 더 진행하지 않고 꽃의 품종을 setosa로 분류한다.
또, 만약 꽃잎이 2.45cm보다 길다면 오른쪽 노드로 이동한다. 이번에는 꽃잎이 너비가 1.75cm보다 작은지 큰지를 검사해서 작다면 versicolor, 크다면 virginica로 분류한다.
노드의 sample 속성은 노드에서 각 클래스에 얼마나 많은 훈련 샘플이 있는지 알려준다. 그리고 gini 속성은 impurity를 측정한다. 한 노드의 모든 샘플이 같은 클래스에 속해 있다면 이 노드를 순수(gini=0)하다고 한다. 위의 그림에 주황색 리프 노드의 경우에 순수하다고 할 수 있다.
CART(classification and regression tree) 훈련 알고리즘
사이킷런은 결정 트리를 훈련시키기 위해 CART 알고리즘을 사용한다. 먼저 훈련 세트를 하나의 특성 k의 임곗값 t_k를 사용해서 두 개의 서브셋으로 나눈다. 가장 순수한 서브셋으로 나눌 수 있는 (k, t_k) 짝을 찾는다. 이를 최대 깊이가 될 때까지 또는 불순도를 줄이는 분할을 찾을 수 없을 때까지 반복한다.
CART 비용 함수: J(k,t_k) = m_left/m*G_left + m_right/m*G_right

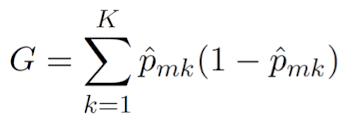
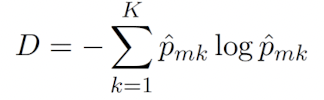
Gini index와 cross-entropy는 수적으로 굉장히 비슷하다고 한다.
기본적으로 지니 인덱스가 사용되지만 criterion 매개변수를 "entropy"로 지정하여 엔트로피 인덱스를 사용할 수 있다.
DecisionTreeClassifier(criterion='entropy')from matplotlib.colors import ListedColormap def plot_decision_boundary(clf, X, y, axes=[0, 7.5, 0, 3], iris=True, legend=False, plot_training=True): x1s = np.linspace(axes[0], axes[1], 100) x2s = np.linspace(axes[2], axes[3], 100) x1, x2 = np.meshgrid(x1s, x2s) X_new = np.c_[x1.ravel(), x2.ravel()] y_pred = clf.predict(X_new).reshape(x1.shape) custom_cmap = ListedColormap(['#fafab0','#9898ff','#a0faa0']) plt.contourf(x1, x2, y_pred, alpha=0.3, cmap=custom_cmap) if not iris: custom_cmap2 = ListedColormap(['#7d7d58','#4c4c7f','#507d50']) plt.contour(x1, x2, y_pred, cmap=custom_cmap2, alpha=0.8) if plot_training: plt.plot(X[:, 0][y==0], X[:, 1][y==0], "yo", label="Iris setosa") plt.plot(X[:, 0][y==1], X[:, 1][y==1], "bs", label="Iris versicolor") plt.plot(X[:, 0][y==2], X[:, 1][y==2], "g^", label="Iris virginica") plt.axis(axes) if iris: plt.xlabel("Petal length", fontsize=14) plt.ylabel("Petal width", fontsize=14) else: plt.xlabel(r"$x_1$", fontsize=18) plt.ylabel(r"$x_2$", fontsize=18, rotation=0) if legend: plt.legend(loc="lower right", fontsize=14) plt.figure(figsize=(8, 4)) plot_decision_boundary(tree_clf, X, y) plt.plot([2.45, 2.45], [0, 3], "k-", linewidth=2) plt.plot([2.45, 7.5], [1.75, 1.75], "k--", linewidth=2) plt.plot([4.95, 4.95], [0, 1.75], "k:", linewidth=2) plt.plot([4.85, 4.85], [1.75, 3], "k:", linewidth=2) plt.text(1.40, 1.0, "Depth=0", fontsize=15) plt.text(3.2, 1.80, "Depth=1", fontsize=13) plt.text(4.05, 0.5, "(Depth=2)", fontsize=11) save_fig("decision_tree_decision_boundaries_plot") plt.show()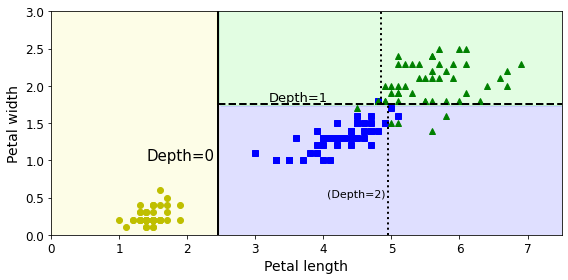
위 그림은 이 결정 트리의 결정 경계를 보여준다. max_dept를 2로 설정했기 때문에 영역이 세 개로 나누어진 것을 볼 수 있다.
모델 해석 - 화이트박스 모델과 블랙박스 모델
결정 트리는 직관적이고 결정 방식을 이해하기가 쉽다. 이런 모델을 화이트 박스 모델이라 한다. 반면에 랜덤 포레스트와 같은 모델은 블랙박스 모델이다. 이 알고리즘은 성능이 뛰어나고 예측을 만드는 연산 과정을 쉽게 확인할 수 있지만 왜 그런 예측을 만드는지는 쉽게 설명하기 어렵다.
계산복잡도
예측을 하려면 결정 트리를 루트 노드에서 리프 노드까지 탐색해야한다. 일반적으로 결정 트리는 거의 균형을 이루고 있으므로 O(log_2(m))개의 노드를 거치게 된다.
클래스 확률 추정
결정트리는 한 샘플이 특정 클래스 k에 속할 확률을 추정할 수도 있다.
tree_clf.predict_proba([[5, 1.5]]) # 출력: array([[0. , 0.90740741, 0.09259259]])tree_clf.predict([[5, 1.5]]) # 출력: array([1])규제 매개변수
결정 트리는 훈련 데이터에 대한 제약 사항이 거의 없기 때문에 제한을 두지 않으면 트리가 훈련 데이터에 아주 가깝게 맞추려고 해서 과대적합 되기가 쉽다. 결정트리와 같이 훈련되기 전까지 파라미터 수가 결정되지 않는 모델을 비파라미터 모델(nonparametric model)이라 한다.
과대적합을 위해 모델을 규제하기 위해 사이킷런에서는 max_depth 매개변수를 사용할 수 있다.
DecisionTreeClassifier에는 min_samples_split, min_samples_leaf, min_weight_fraction_leaf, max_leaf_nodes, max_features가 있다.
tree_clf_tweaked = DecisionTreeClassifier(max_depth=2, random_state=40) tree_clf_tweaked.fit(X, y) # 출력: DecisionTreeClassifier(max_depth=2, random_state=40)plt.figure(figsize=(8, 4)) plot_decision_boundary(tree_clf_tweaked, X, y, legend=False) plt.plot([0, 7.5], [0.8, 0.8], "k-", linewidth=2) plt.plot([0, 7.5], [1.75, 1.75], "k--", linewidth=2) plt.text(1.0, 0.9, "Depth=0", fontsize=15) plt.text(1.0, 1.80, "Depth=1", fontsize=13) save_fig("decision_tree_instability_plot") plt.show()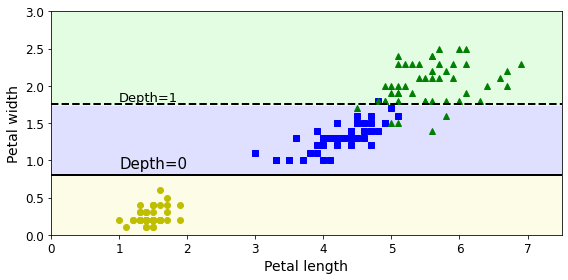
from sklearn.datasets import make_moons Xm, ym = make_moons(n_samples=100, noise=0.25, random_state=53) deep_tree_clf1 = DecisionTreeClassifier(random_state=42) deep_tree_clf2 = DecisionTreeClassifier(min_samples_leaf=4, random_state=42) deep_tree_clf1.fit(Xm, ym) deep_tree_clf2.fit(Xm, ym) fig, axes = plt.subplots(ncols=2, figsize=(10, 4), sharey=True) plt.sca(axes[0]) plot_decision_boundary(deep_tree_clf1, Xm, ym, axes=[-1.5, 2.4, -1, 1.5], iris=False) plt.title("No restrictions", fontsize=16) plt.sca(axes[1]) plot_decision_boundary(deep_tree_clf2, Xm, ym, axes=[-1.5, 2.4, -1, 1.5], iris=False) plt.title("min_samples_leaf = {}".format(deep_tree_clf2.min_samples_leaf), fontsize=14) plt.ylabel("") save_fig("min_samples_leaf_plot") plt.show()min_sample_leaf 파라미터는 리프 노드가 가지는 샘플의 최소 수를 정의한다.
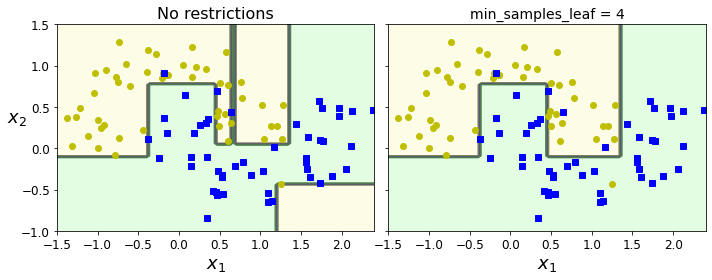
왼쪽 모델은 과대적합되었고 오른쪽 모델이 더 성능이 좋을 것으로 보인다.
angle = np.pi / 180 * 20 rotation_matrix = np.array([[np.cos(angle), -np.sin(angle)], [np.sin(angle), np.cos(angle)]]) Xr = X.dot(rotation_matrix) tree_clf_r = DecisionTreeClassifier(random_state=42) tree_clf_r.fit(Xr, y) plt.figure(figsize=(8, 3)) plot_decision_boundary(tree_clf_r, Xr, y, axes=[0.5, 7.5, -1.0, 1], iris=False) plt.show()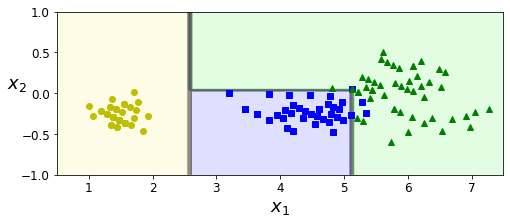
np.random.seed(6) Xs = np.random.rand(100, 2) - 0.5 ys = (Xs[:, 0] > 0).astype(np.float32) * 2 angle = np.pi / 4 rotation_matrix = np.array([[np.cos(angle), -np.sin(angle)], [np.sin(angle), np.cos(angle)]]) Xsr = Xs.dot(rotation_matrix) tree_clf_s = DecisionTreeClassifier(random_state=42) tree_clf_s.fit(Xs, ys) tree_clf_sr = DecisionTreeClassifier(random_state=42) tree_clf_sr.fit(Xsr, ys) fig, axes = plt.subplots(ncols=2, figsize=(10, 4), sharey=True) plt.sca(axes[0]) plot_decision_boundary(tree_clf_s, Xs, ys, axes=[-0.7, 0.7, -0.7, 0.7], iris=False) plt.sca(axes[1]) plot_decision_boundary(tree_clf_sr, Xsr, ys, axes=[-0.7, 0.7, -0.7, 0.7], iris=False) plt.ylabel("") save_fig("sensitivity_to_rotation_plot") plt.show()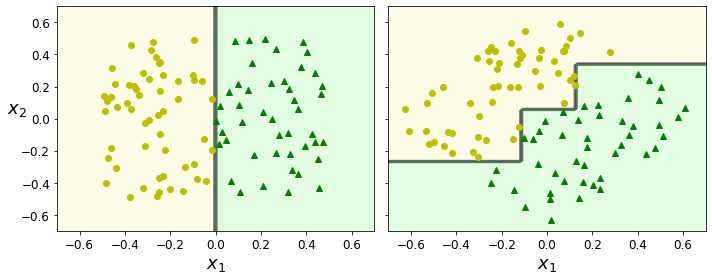
결정 트리는 이해하고 해석하기 쉽고 여러 용도로 사용할 수 있으며 해석하기 용이하다는 장점이 있지만 훈련 데이터에 있는 작은 변화에도 매우 민감하다는 문제가 있다. 결정 트리는 계단 모양의 결정 경계를 만든다는 점에서 훈련 세트의 회전에 민감하게 반응하게 된다. 이러한 문제를 해결하는 한가지 방법은 훈련 데이터를 더 좋은 방향으로 회전시키는 PCA 기법을 사용하는 것이다.
회귀 트리
결정 트리는 회귀 문제에도 사용될 수 있다. 사이킷런의 DecisionTreeRegressor을 사용해 회귀 트리를 만들 수 있다.
회귀 모델은 CART 알고리즘에서 훈련 세트를 불순도를 최소화하는 방향으로 분할하는 대신 MSE를 최소화하도록 분할하는 것을 제외하고는 앞서 설명한 것과 거의 똑같이 작용한다.
# 2차식으로 만든 데이터셋 + 잡음 np.random.seed(42) m = 200 X = np.random.rand(m, 1) y = 4 * (X - 0.5) ** 2 y = y + np.random.randn(m, 1) / 10from sklearn.tree import DecisionTreeRegressor tree_reg = DecisionTreeRegressor(max_depth=2, random_state=42) tree_reg.fit(X, y)from sklearn.tree import DecisionTreeRegressor tree_reg1 = DecisionTreeRegressor(random_state=42, max_depth=2) tree_reg2 = DecisionTreeRegressor(random_state=42, max_depth=3) tree_reg1.fit(X, y) tree_reg2.fit(X, y) def plot_regression_predictions(tree_reg, X, y, axes=[0, 1, -0.2, 1], ylabel="$y$"): x1 = np.linspace(axes[0], axes[1], 500).reshape(-1, 1) y_pred = tree_reg.predict(x1) plt.axis(axes) plt.xlabel("$x_1$", fontsize=18) if ylabel: plt.ylabel(ylabel, fontsize=18, rotation=0) plt.plot(X, y, "b.") plt.plot(x1, y_pred, "r.-", linewidth=2, label=r"$\hat{y}$") fig, axes = plt.subplots(ncols=2, figsize=(10, 4), sharey=True) plt.sca(axes[0]) plot_regression_predictions(tree_reg1, X, y) for split, style in ((0.1973, "k-"), (0.0917, "k--"), (0.7718, "k--")): plt.plot([split, split], [-0.2, 1], style, linewidth=2) plt.text(0.21, 0.65, "Depth=0", fontsize=15) plt.text(0.01, 0.2, "Depth=1", fontsize=13) plt.text(0.65, 0.8, "Depth=1", fontsize=13) plt.legend(loc="upper center", fontsize=18) plt.title("max_depth=2", fontsize=14) plt.sca(axes[1]) plot_regression_predictions(tree_reg2, X, y, ylabel=None) for split, style in ((0.1973, "k-"), (0.0917, "k--"), (0.7718, "k--")): plt.plot([split, split], [-0.2, 1], style, linewidth=2) for split in (0.0458, 0.1298, 0.2873, 0.9040): plt.plot([split, split], [-0.2, 1], "k:", linewidth=1) plt.text(0.3, 0.5, "Depth=2", fontsize=13) plt.title("max_depth=3", fontsize=14) save_fig("tree_regression_plot") plt.show()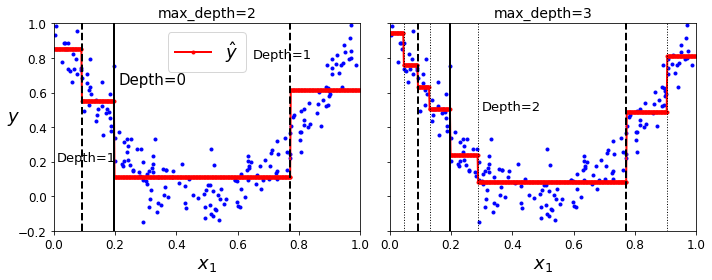
export_graphviz( tree_reg1, out_file=os.path.join(IMAGES_PATH, "regression_tree.dot"), feature_names=["x1"], rounded=True, filled=True )Source.from_file(os.path.join(IMAGES_PATH, "regression_tree.dot"))
분류 모델에서 Gini로 표시되었던 부분이 squared_error로 표시되어있는 것을 볼 수 있다.
노드의 색은 값의 크기가 크면 진하게, 작으면 연하게 표시되어있다.
tree_reg1 = DecisionTreeRegressor(random_state=42) tree_reg2 = DecisionTreeRegressor(random_state=42, min_samples_leaf=10) tree_reg1.fit(X, y) tree_reg2.fit(X, y) x1 = np.linspace(0, 1, 500).reshape(-1, 1) y_pred1 = tree_reg1.predict(x1) y_pred2 = tree_reg2.predict(x1) fig, axes = plt.subplots(ncols=2, figsize=(10, 4), sharey=True) plt.sca(axes[0]) plt.plot(X, y, "b.") plt.plot(x1, y_pred1, "r.-", linewidth=2, label=r"$\hat{y}$") plt.axis([0, 1, -0.2, 1.1]) plt.xlabel("$x_1$", fontsize=18) plt.ylabel("$y$", fontsize=18, rotation=0) plt.legend(loc="upper center", fontsize=18) plt.title("No restrictions", fontsize=14) plt.sca(axes[1]) plt.plot(X, y, "b.") plt.plot(x1, y_pred2, "r.-", linewidth=2, label=r"$\hat{y}$") plt.axis([0, 1, -0.2, 1.1]) plt.xlabel("$x_1$", fontsize=18) plt.title("min_samples_leaf={}".format(tree_reg2.min_samples_leaf), fontsize=14) save_fig("tree_regression_regularization_plot") plt.show()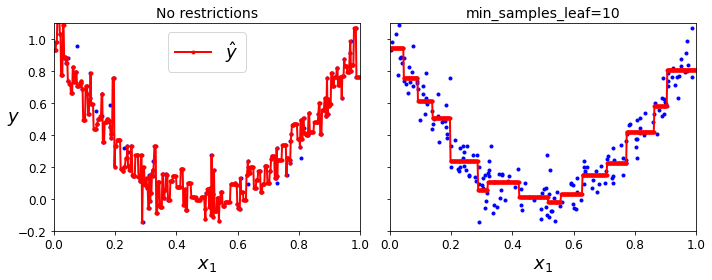
min_samples_leaf 규제를 적절하게 함으로써 트리의 모양이 조금더 2차 곡선에 가까워진 것을 볼 수 있다.
문제
1. 파이썬에서 결정 트리를 시각화 할 수 있는 방법 두가지를 소개하시오
2. classification tree 와 regression tree의 cart 비용함수의 차이점을 서술하시오
3. min_samples_leaf 파라미터의 역할을 말하시오
4. 결정 트리의 주된 문제점은 무엇인가
5. value = [2,1,45]와 같이 세가지의 클래스에 대해 각각 0, 1, 45개로 분류한 노드의 gini index 값을 구하시오
'핸즈온머신러닝' 카테고리의 다른 글
핸즈온 머신러닝[5] 서포트 벡터 머신(3) (0) 2022.07.05 핸즈온 머신러닝[5] 서포트 벡터 머신(2) (0) 2022.07.03 핸즈온 머신러닝[5] 서포트 벡터 머신(1) (0) 2022.06.22 핸즈온 머신러닝[4] 모델 훈련(3) (0) 2022.06.14 핸즈온 머신러닝[4] 모델 훈련(2) (0) 2022.06.13