-
핸즈온 머신러닝[3] 분류(2)핸즈온머신러닝 2022. 5. 5. 13:40
https://www.youtube.com/watch?v=Ie5pFrpKyvM&list=PLJN246lAkhQjX3LOdLVnfdFaCbGouEBeb&index=12
거짓 양성 비율에 대한 진짜 양성 비율 곡선 (Receiver Operating Characteristic)
from sklearn.metrics import roc_curve fpr, tpr, thresholds = roc_curve(y_train_5, y_scores)fpr: 특이도, tpr: 민감도
def plot_roc_curve(fpr, tpr, label=None): plt.plot(fpr, tpr, linewidth=2, label=label) plt.plot([0, 1], [0, 1], 'k--') # 대각 점선 plt.axis([0, 1, 0, 1]) # Not shown in the book plt.xlabel('False Positive Rate (Fall-Out)', fontsize=16) # Not shown plt.ylabel('True Positive Rate (Recall)', fontsize=16) # Not shown plt.grid(True) # Not shown plt.figure(figsize=(8, 6)) # Not shown plot_roc_curve(fpr, tpr) fpr_90 = fpr[np.argmax(tpr >= recall_90_precision)] # Not shown plt.plot([fpr_90, fpr_90], [0., recall_90_precision], "r:") # Not shown plt.plot([0.0, fpr_90], [recall_90_precision, recall_90_precision], "r:") # Not shown plt.plot([fpr_90], [recall_90_precision], "ro") # Not shown save_fig("roc_curve_plot") # Not shown plt.show()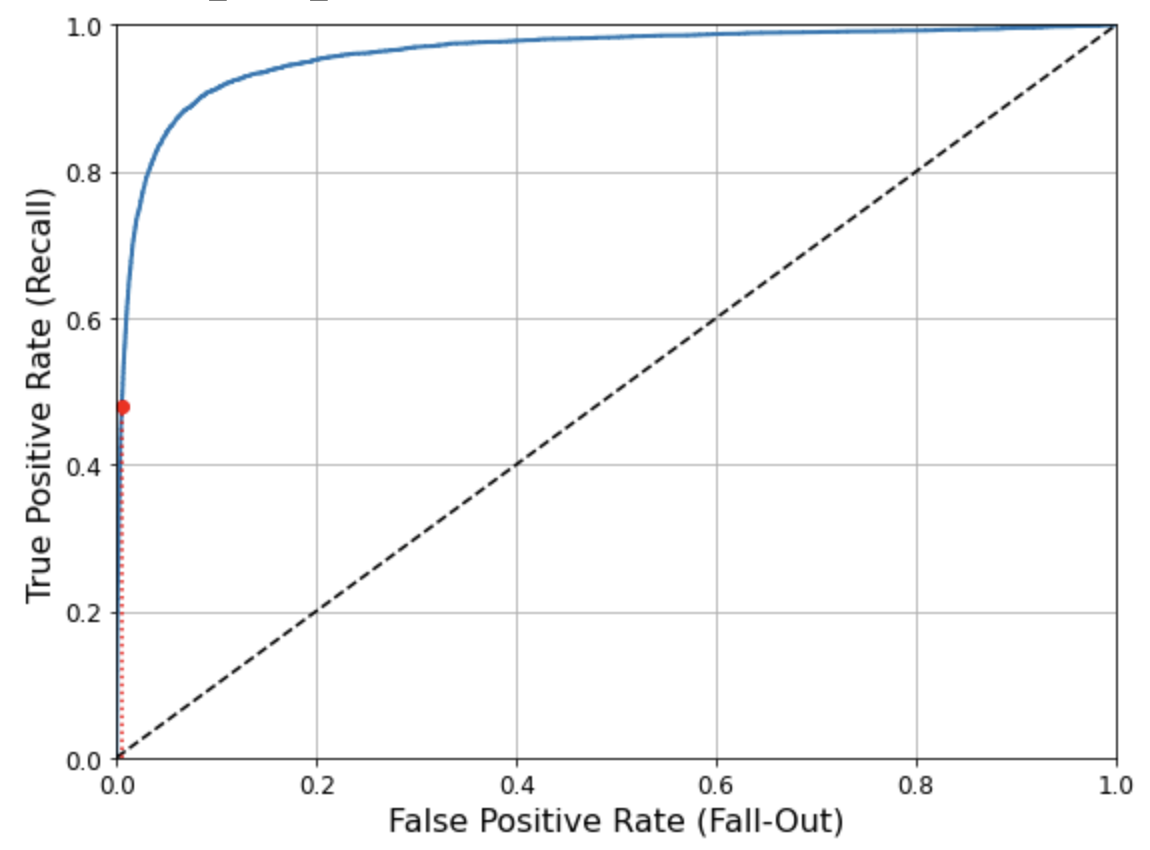
왼쪽 위의 끝으로 갈수록 좋음
from sklearn.metrics import roc_auc_score roc_auc_score(y_train_5, y_scores)0.9604938554008616
roc_auc_score: 면적을 계산
from sklearn.ensemble import RandomForestClassifier forest_clf = RandomForestClassifier(n_estimators=100, random_state=42) y_probas_forest = cross_val_predict(forest_clf, X_train, y_train_5, cv=3, method="predict_proba")100개의 결정트리로 훈련
predict_proba: 예측이 아닌 예측의 확률값을 제공
y_scores_forest = y_probas_forest[:, 1] # 점수 = 양성 클래스의 확률 fpr_forest, tpr_forest, thresholds_forest = roc_curve(y_train_5,y_scores_forest)recall_for_forest = tpr_forest[np.argmax(fpr_forest >= fpr_90)] plt.figure(figsize=(8, 6)) plt.plot(fpr, tpr, "b:", linewidth=2, label="SGD") plot_roc_curve(fpr_forest, tpr_forest, "Random Forest") plt.plot([fpr_90, fpr_90], [0., recall_90_precision], "r:") plt.plot([0.0, fpr_90], [recall_90_precision, recall_90_precision], "r:") plt.plot([fpr_90], [recall_90_precision], "ro") plt.plot([fpr_90, fpr_90], [0., recall_for_forest], "r:") plt.plot([fpr_90], [recall_for_forest], "ro") plt.grid(True) plt.legend(loc="lower right", fontsize=16) save_fig("roc_curve_comparison_plot") plt.show()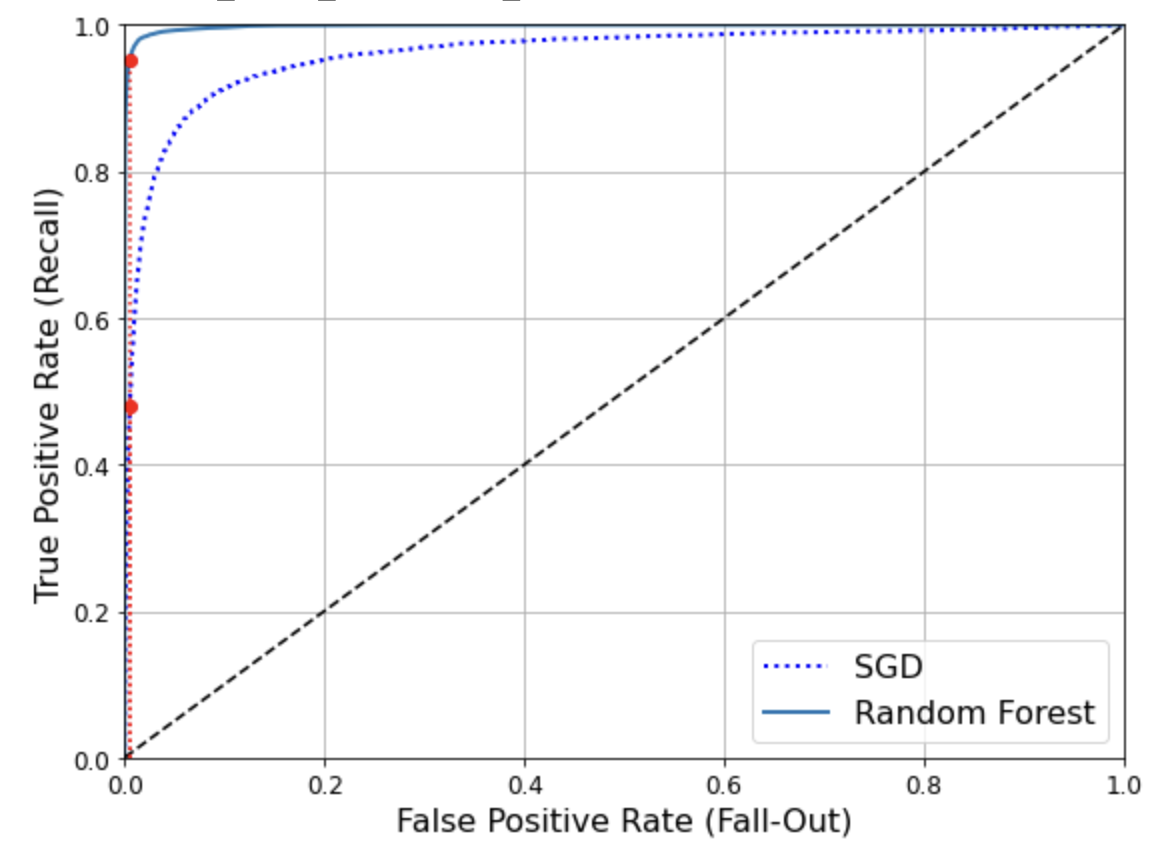
roc_auc_score(y_train_5, y_scores_forest)0.9983436731328145
y_train_pred_forest = cross_val_predict(forest_clf, X_train, y_train_5, cv=3) precision_score(y_train_5, y_train_pred_forest)0.9905083315756169
recall_score(y_train_5, y_train_pred_forest)다중 분류
OvR, OvA, OvO
from sklearn.svm import SVC svm_clf = SVC(gamma="auto", random_state=42) svm_clf.fit(X_train[:1000], y_train[:1000]) # y_train_5이 아니라 y_train입니다 svm_clf.predict([some_digit])array([5], dtype=uint8)
some_digit_scores = svm_clf.decision_function([some_digit]) some_digit_scoresarray([[ 2.81585438, 7.09167958, 3.82972099, 0.79365551, 5.8885703 , 9.29718395, 1.79862509, 8.10392157, -0.228207 , 4.83753243]])
이 값들 중 가장 높은 점수의 값이 예측값이 됨 여기서는 9.29718395
np.argmax(some_digit_scores)5
svm_clf.classes_array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=uint8)
svm_clf.classes_[5]5
from sklearn.multiclass import OneVsRestClassifier ovr_clf = OneVsRestClassifier(SVC(gamma="auto", random_state=42)) ovr_clf.fit(X_train[:1000], y_train[:1000]) ovr_clf.predict([some_digit])array([5], dtype=uint8)
len(ovr_clf.estimators_)10
sgd_clf.fit(X_train, y_train) sgd_clf.predict([some_digit])array([3], dtype=uint8)
sgd_clf.decision_function([some_digit])array([[-31893.03095419, -34419.69069632, -9530.63950739, 1823.73154031, -22320.14822878, -1385.80478895, -26188.91070951, -16147.51323997, -4604.35491274, -12050.767298 ]])cross_val_score(sgd_clf, X_train, y_train, cv=3, scoring="accuracy")array([0.87365, 0.85835, 0.8689 ])
from sklearn.preprocessing import StandardScaler scaler = StandardScaler() X_train_scaled = scaler.fit_transform(X_train.astype(np.float64)) cross_val_score(sgd_clf, X_train_scaled, y_train, cv=3, scoring="accuracy")array([0.8983, 0.891 , 0.9018])
경사하강법 -> 거리에 민감해서 scale을 조정해줘야함
에러 분석
다중분류인 경우 오차행렬
y_train_pred = cross_val_predict(sgd_clf, X_train_scaled, y_train, cv=3) conf_mx = confusion_matrix(y_train, y_train_pred) conf_mx
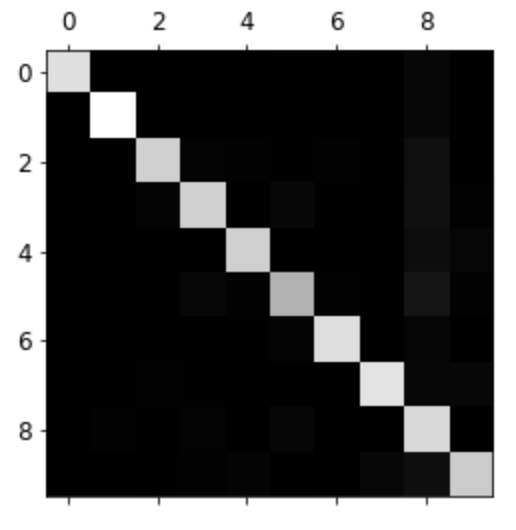
def plot_confusion_matrix(matrix): """If you prefer color and a colorbar""" fig = plt.figure(figsize=(8,8)) ax = fig.add_subplot(111) cax = ax.matshow(matrix) fig.colorbar(cax)plt.matshow(conf_mx, cmap=plt.cm.gray) save_fig("confusion_matrix_plot", tight_layout=False) plt.show()높은 값이 밝게 나옴, 어둡게 나온 값이 분류가 잘 되지 않은 값
row_sums = conf_mx.sum(axis=1, keepdims=True) norm_conf_mx = conf_mx / row_sumsnp.fill_diagonal(norm_conf_mx, 0) plt.matshow(norm_conf_mx, cmap=plt.cm.gray) save_fig("confusion_matrix_errors_plot", tight_layout=False) plt.show()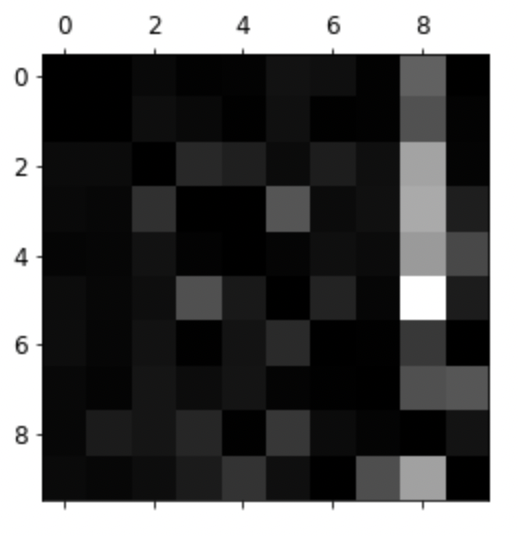
3과 5가 혼돈이 되는 숫자임을 알 수 있음
cl_a, cl_b = 3, 5 X_aa = X_train[(y_train == cl_a) & (y_train_pred == cl_a)] X_ab = X_train[(y_train == cl_a) & (y_train_pred == cl_b)] X_ba = X_train[(y_train == cl_b) & (y_train_pred == cl_a)] X_bb = X_train[(y_train == cl_b) & (y_train_pred == cl_b)] plt.figure(figsize=(8,8)) plt.subplot(221); plot_digits(X_aa[:25], images_per_row=5) plt.subplot(222); plot_digits(X_ab[:25], images_per_row=5) plt.subplot(223); plot_digits(X_ba[:25], images_per_row=5) plt.subplot(224); plot_digits(X_bb[:25], images_per_row=5) save_fig("error_analysis_digits_plot") plt.show()
1. 진짜 3을 3으로 분류한 경우
2. 진짜 3을 5로 잘못 분류한 경우
3. 5를 3으로 잘못 분류
4. 진짜 5를 5로 분류
다중 레이블 분류
from sklearn.neighbors import KNeighborsClassifier y_train_large = (y_train >= 7) y_train_odd = (y_train % 2 == 1) y_multilabel = np.c_[y_train_large, y_train_odd] knn_clf = KNeighborsClassifier() knn_clf.fit(X_train, y_multilabel)타깃값이 7보다 큰지, 타깃값이 홀수인지 두 개의 레이블 (다중 레이블)
KNeighborsClassifier()
knn_clf.predict([some_digit])array([[False, True]])
y_train_knn_pred = cross_val_predict(knn_clf, X_train, y_multilabel, cv=3) f1_score(y_multilabel, y_train_knn_pred, average="macro")0.976410265560605
Macro: 레이블별로 f1 score를 계산해서 평균값을 냄, weighted, micro
noise = np.random.randint(0, 100, (len(X_train), 784)) X_train_mod = X_train + noise noise = np.random.randint(0, 100, (len(X_test), 784)) X_test_mod = X_test + noise y_train_mod = X_train y_test_mod = X_testsome_index = 0 plt.subplot(121); plot_digit(X_test_mod[some_index]) plt.subplot(122); plot_digit(y_test_mod[some_index]) save_fig("noisy_digit_example_plot") plt.show()왼쪽: 노이즈가 섞인 그래프
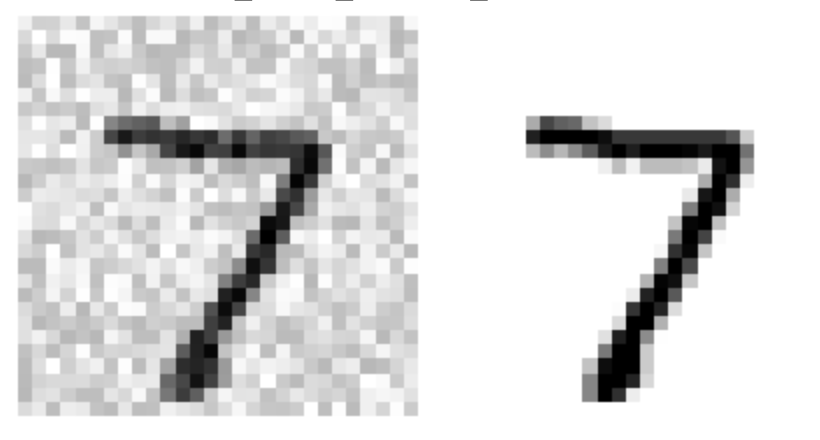
knn_clf.fit(X_train_mod, y_train_mod) clean_digit = knn_clf.predict([X_test_mod[some_index]]) plot_digit(clean_digit) save_fig("cleaned_digit_example_plot")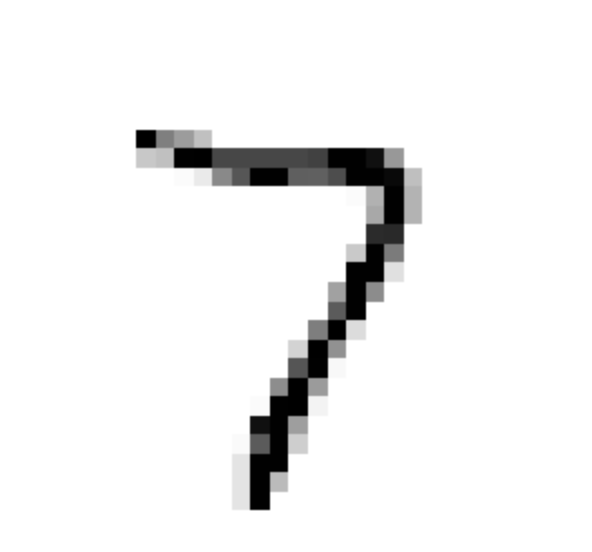
더미 (즉 랜덤) 분류기
from sklearn.dummy import DummyClassifier # 0.24버전부터 strategy의 기본값이 'stratified'에서 'prior'로 바뀌므로 명시적으로 지정합니다. dmy_clf = DummyClassifier(strategy='prior') y_probas_dmy = cross_val_predict(dmy_clf, X_train, y_train_5, cv=3, method="predict_proba") y_scores_dmy = y_probas_dmy[:, 1]fprr, tprr, thresholdsr = roc_curve(y_train_5, y_scores_dmy) plot_roc_curve(fprr, tprr)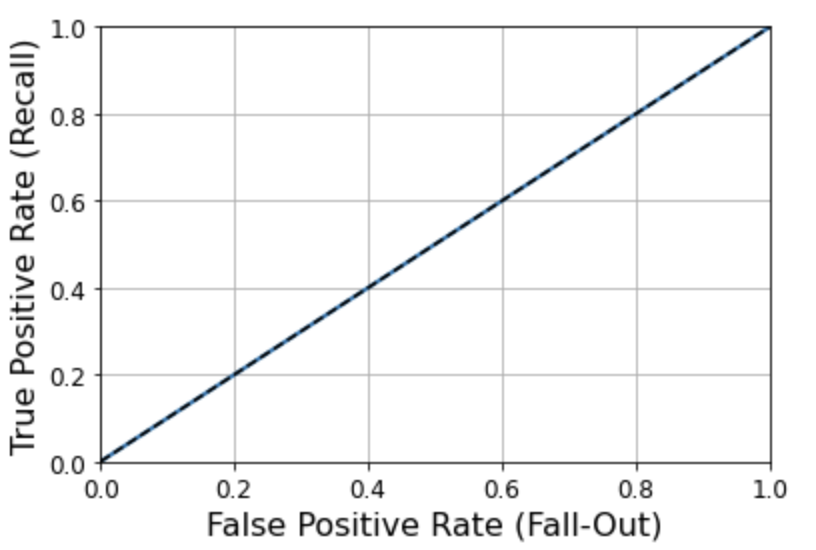
KNN 분류기
from sklearn.neighbors import KNeighborsClassifier knn_clf = KNeighborsClassifier(weights='distance', n_neighbors=4) knn_clf.fit(X_train, y_train)KNeighborsClassifier(n_neighbors=4, weights='distance')
weights='distance': 가까운 거리에 가중치를 크게 줌
y_knn_pred = knn_clf.predict(X_test)from sklearn.metrics import accuracy_score accuracy_score(y_test, y_knn_pred)0.9714
from scipy.ndimage.interpolation import shift def shift_digit(digit_array, dx, dy, new=0): return shift(digit_array.reshape(28, 28), [dy, dx], cval=new).reshape(784) plot_digit(shift_digit(some_digit, 5, 1, new=100))이미지를 이동시키는 함수를 정의함
X_train_expanded = [X_train] y_train_expanded = [y_train] for dx, dy in ((1, 0), (-1, 0), (0, 1), (0, -1)): shifted_images = np.apply_along_axis(shift_digit, axis=1, arr=X_train, dx=dx, dy=dy) X_train_expanded.append(shifted_images) y_train_expanded.append(y_train) X_train_expanded = np.concatenate(X_train_expanded) y_train_expanded = np.concatenate(y_train_expanded) X_train_expanded.shape, y_train_expanded.shape((300000, 784), (300000,))
원본 세트를 네 번 이동함 60000 * 5 = 300000
knn_clf.fit(X_train_expanded, y_train_expanded)KNeighborsClassifier(n_neighbors=4, weights='distance')
y_knn_expanded_pred = knn_clf.predict(X_test)accuracy_score(y_test, y_knn_expanded_pred)0.9763
ambiguous_digit = X_test[2589] knn_clf.predict_proba([ambiguous_digit])
plot_digit(ambiguous_digit)
문제
- ROC 곡선이 무엇인지 그리고 ROC 곡선이 어떤 모양을 띄는 것이 더 좋은 분류기를 나타내는지 설명하시오
- ROC 곡선 밑의 면적을 계산해주는 sklearn의 함수 이름이 무엇인가?
- 다중분류에서 OvO, OvA, OvR이 무엇인지 설명하시오
- f1_score(y_multilabel, y_train_knn_pred, average="macro") 다음 코드에서 fi_score를 계산하는 함수의 average 파라미터 값이 Macro, weighted, micro 일때의 기능 차이를 설명하시오

3. 위의 사진은 다중 분류의 오차 행렬을 matshow 함수로 cmap 파라미터 값을 plt.cm.gray로 두고 그린 그래프이다 그래프가 무엇을 나타내는지 설명하시오
'핸즈온머신러닝' 카테고리의 다른 글
핸즈온 머신러닝[4] 모델 훈련(2) (0) 2022.06.13 핸즈온 머신러닝[4] 모델 훈련(1) (0) 2022.05.13 핸즈온 머신러닝[3] 분류(1) (0) 2022.05.04 핸즈온 머신러닝[2] 머신러닝 프로젝트 처음부터 끝까지(3) (0) 2022.04.28 핸즈온 머신러닝[2] 머신러닝 프로젝트 처음부터 끝까지(2) (0) 2022.04.25