-
An Introduction to Vision-Language Modeling 논문 요약Computer Vision 2024. 8. 28. 10:44
https://arxiv.org/pdf/2405.17247
목차
1. Introduction2. The Families of VLMs3. A Guide to VLM Training4. Extending VLMs to Videos1. Introduction
Vision Language Model이란?
- “In simple terms, a VLM can understand images and text jointly and relate them together”
- VLM은 단순히 정의하면, 영상과 텍스트를 결합하여 이해하고 연관 지을 수 있는 모델을 말한다.
- 근래의 VLM 모델은 대부분 Transformer에 기반하고 있으며, 일반적으로 이미지 모델, 텍스트 모델 그리고 두 개의 모달리티를 결합하는 모듈 이렇게 세 가지의 요소로 구성되어 있다.

2. The Families of VLMs
Early Works on VLMs based on Transformers
- 초기의 VLM 연구로는 대표적으로 VL BERT(2019)와 ViL BERT(2019)가 있다.
- 이 두 가지 모델은 이 당시에 좋은 성능을 보이던 BERT를 visual 영역로 확장시킨 모델로, Object detection 모듈을 사용해서 ROI 영역을 추출하고, 이를 CNN에 통과시켜 나온 피쳐를 텍스트 피쳐와 같이 BERT에 입력하는 방식을 사용했다.
- 또한, BERT에서 사용된 self-supervised 기법인 next sentence prediction과 Masked Language Modeling을 확장시켜서,Masked multi-modal learning과 Multi-modal alignment prediction 두 가지의 objective로 학습시킨 것이 가장 큰 특징이다.
- 두 모델의 차이점으로는, VL BERT는 이미지와 텍스트의 feature를 융합하여 한 가지 모델에 주입한 반면, ViL BERT는 두 가지의 분리된 path를 사용하고 co-attention transformer layer로 두 가지 모달리티를 융합했다는 점이다.

Su, Weijie, et al. "Vl-bert: Pre-training of generic visual-linguistic representations." arXiv preprint arXiv:1908.08530 (2019). 

Lu, Jiasen, et al. "Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks." Advances in neural information processing systems 32 (2019). The Families of VLMs
- 이 논문에서는 VLM을 크게 네 가지의 카테고리로 분류하고 있다.
- Contrastive Learning에 기반한 VLM: 텍스트와 이미지의 positive pair 그러니까 대응되는 쌍의 임베딩은 높은 similarity score를 갖도록 하며, 반대의 경우에는 낮은 similarity를 갖도록 학습하는 방법을 사용한다.
- Masking 기법에 기반한 VLM: 주어진 텍스트로 마스킹된 이미지의 영역을 맞추거나, 또는 주어진 이미지로 마스킹된 텍스트 영역을 맞추도록 학습된 모델이다. 위의 두 가지 방법은 두 모달리티를 결합하여 학습하면서도 대량의 라벨이 없는 데이터를 효과적으로 활용할 수 있는 self-supervised 기법을 사용한다.
- Pretrained backbone: Llama와 같은 오픈소스 LLM을 가져와서 사용하는 방식으로, 전체 모델을 scratch 부터 학습하는 것이 아닌 매핑 네트워크만을 scratch 부터 학습하면 된다는 점에서 비교적 효율적인 방법이다.
- Generative model: 문장에서 이미지, 또는 이미지에서 문장을 생성하는 모델이다.
Contrastive-based VLMs
- 첫 번째 카테고리인 Contrastive based VLM에 해당하는 모델로서 대표적으로 CLIP(2021)이 있다.
- CLIP은 text encoder와 image encoder를 사용해서 두 가지의 모달리티를 임베딩하고, Contrastive Learning 기법을 사용하여 텍스트 설명과 이미지가 embedding space 상에서 가깝게 위치하는 것을 목표로 학습한 모델이다.
- CLIP은 web에서 크롤링된 대량의 image-text pair 데이터셋을 통해 학습되었으며, Zero-shot classification에서 좋은 성능을 보이는데, 구체적으로는 이렇게 정해진 형식의 텍스트에서, 빈칸 안에 들어있는 단어를 바꿈으로써 여러 후보 prompt 중에 이미지와 가장 similarity score가 높은 prompt에 들어있는 단어를 그 이미지의 class로 분류하는 방식으로 동작한다.
- 한 가지 흥미로운 사실은, 상황에 맞는 적절한 prompt를 사용하거나, 여러 prompt의 결과를 앙상블함으로써 성능 차이가 있다는 점인데, prompt tuning을 통해서만, imageNet classification 성능을 5% 정도 향상시켰다고 한다.


Radford, Alec, et al. "Learning transferable visual models from natural language supervision." International conference on machine learning . PMLR, 2021. - CLIP에 변형을 주어 발전시킨 모델로는 SigLip (2023)과 Llip(2024)이 있다.
- SigLIP은 CLIP의 Softmax 기반의 objective를 sigmoid 기반으로 변경한 모델로, 기존에 softmax에 존재하는 Normalize term이 batch 내에 존재하는 다른 데이터에 영향을 받기 때문에, CLIP이 batch 크기에 민감하다는 점에 주목하여 이 항을 없애고, sigmoid 함수를 통해 각 이미지-텍스트 pair가 대응되는지 또는 대응되지 않는지를 독립적으로 평가하여 학습하는 방식으로 변경하였다.
- 이렇게 되면, batch 단위로 모든 pair-wise similarity를 기억할 필요가 없고, 작은 batch size에 대해서도 CLIP보다 좋은 성능을 낸다.

Zhai, Xiaohua, et al. "Sigmoid loss for language image pre-training." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023. - Llip은 이미지에 대응되는 텍스트가 여러개 존재할 수 있다는 사실에 기반하며, 한 개의 이미지가 embedding space 상에서 여러개의 대응되는 feature를 가질 수 있도록 한다.
- 이를 위해, image encoder는 K개의 토큰을 출력하고, 텍스트 임베딩과의 cross-attention을 통해 이 토큰들에 weighted average를 주어, 각각의 text embedding과 이에 대응하는 visual feature에 대해 contrastive loss로 학습할 수 있도록 변경하였다.

Lavoie, Samuel, et al. "Modeling caption diversity in contrastive vision-language pretraining." arXiv preprint arXiv:2405.00740(2024). Generative-based VLMs
- generative based model로 대표적으로 CoCa(2022) 가 있다.
- CoCa는, CLIP의 contrastive loss에 generative loss를 추가해서 text generation을 수행하는 모델이다.
- 이를 위해 encoder-decoder 구조를 사용하며, decoder를 Unimodel text decoder와 multimodal text decdoer 두 가지 유닛으로 나누고, 유니모달 레이어에서는 cross-attention을 사용하지 않고 text representation 만을 학습하도록 하여 image representation과의 contrastive loss를 계산하도록 하였으며, 멀티모달 레이어에서는 caption generation을 수행하여 captioning loss로 학습할 수 있도록 했다.


Yu, Jiahui, et al. "Coca: Contrastive captioners are image-text foundation models." arXiv preprint arXiv:2205.01917 (2022). - CM3Leon(2023)은 CoCa와는 달리, text-to-image, image-to-text generation를 모두 제공하는 모델이다.
- A Causal Masked Multimodal Model(CM3) 아키텍처에 기반하는데, CM3 모델은 Causal Language Model과 Masked Language Model의 방식을 결합해서, auto regressive한 방식으로 토큰을 생성하면서도, 문장, 또는 이미지의 부분을 마스킹하고,이 부분을 마지막에 생성함으로써, 양방향 정보를 활용한다는 특성을 가지고 있다.
- 또한, CM3 모델은 HTML 언어로 이루어진 대규모 웹 데이터와 Wikipedia 문서에 대해 학습되었고, 이미지의 경우에는 VQ-VAE-GAN에서 생성한 임베딩을 사용했다
- CM3Leon은 이러한 CM3 아키텍처를 사용하면서도, Document Retrieval Augmentation 기법을 사용하여, 주어진 학습 데이터와 유사한 도큐먼트의 이미지와 텍스트를 append하고 그 뒤에 올 문장이나 이미지를 예측하는 방식으로 학습한 후에, 이미지와 텍스트를 포함하는 다양한 멀티 테스크에 대해서 supervised fine-tuning을 적용함으로써 성능 향상을 도출하였다.


Yu, Lili, et al. "Scaling autoregressive multi-modal models: Pretraining and instruction tuning." arXiv preprint arXiv:2309.02591 2.3 (2023). - Chameleon (2024)모델은 CM3Leon 모델을 확장하여, 텍스트와 이미지가 interleave된 컨텐츠를 처리하면서도, 이미지와 텍스트를 별도로 인코딩하지 않고, 초기부터 결합하여 학습하는 “Early Fusion” 방식을 사용한다.
- Early Fusion 방식은 Gemini에서도 사용되었지만, gemini는 이미지와 텍스트에 대해 별개의 디코더를 사용한 반면에 카멜레옹은 디코더 부분까지 통합된 모듈로 엔드 투 엔드로 동작한다는 차이점이 있다.

Team, Chameleon. "Chameleon: Mixed-modal early-fusion foundation models." arXiv preprint arXiv:2405.09818 (2024). 
Gemini VLMs with masking objectives
- Masking Objective에 기반한 모델로는 FLAVA(2022)라는 모델이 있다.
- FLAVA는 Image Encoder, Text Encoder, Multimodal task head로 구성되며, 각각의 모듈에서 세 가지의 Masking Loss인 Mask Language Modeling, Masked image modeling, masked multimodal modeling을 통해 유니모달 데이터셋인 이미지, 텍스트 기반의 데이터셋과 멀티모달 데이터셋을 모두 활용하여 학습
- 한다.이렇게 학습된 모델은, 각 모듈에 Classification head를 달아서, 이미지 Classification과 같은 Visual Recognition Task, Language Understanding, 그리고 multimodal reasoning과 같은 downstream task를 수행할 수 있다.


Singh, Amanpreet, et al. "Flava: A foundational language and vision alignment model." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022. VLMs from Pretrained Backbones
- MLLM (Multimodel-large language model)은 아래의 그림에 나와있는 것처럼, 보통 Modality encoder와 LLM, 그리고 텍스트를 제외한 모달리티를 LLM의 입력으로 변환하기 위한 connector 이렇게 세 가지의 모듈로 구성된다.
- MLLM에 자주 쓰이는 LLM으로는 LLaMA, Vicuna, Qwen, Flan-T5 등이 있으며, connector의 경우 크게 세 가지로 나눌 수 있는데, MLP에 기반한 Projection-base, Learnable query를 활용하는 Query base, Attention 연산 기반의 fusion based connector로 나눌 수 있다.


https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models
- MLLM의 초기 연구로는 대표적으로 Frozen(2021)이 있다.
- Frozen은 vision encoder로 resnet을, Language model로는 Transformer를 사용하며, 매핑 네트워크로 Visual Feature를 text token embedding으로 projection하는 linear layer를 활용하여 학습시에는 language model은 열려두고, vision encoder와 mapping network만을 학습하는 방법을 사용했다.


Tsimpoukelli, Maria, et al. "Multimodal few-shot learning with frozen language models." Advances in Neural Information Processing Systems 34 (2021): 200-212. - Mini GPT-4(2023)의 경우에도 frozen과 유사하게 vision encoder로 BLIP의 ViT와 Q-Former를, LLM으로는 Vicuna를 활용하였으며, Mapping network로는 linear projection layer를 사용한다.
- Mini GPT-5(2023)는 이러한 Mini GPT-4 모델을 확장하여, 이미지와 텍스트를 둘 다 생성할 수 있는 모델로 변형하였다.
- 구체적으로는 LLM이 ”generative token”을 생성하도록 하고, 이를 feature vector로 매핑 후, stable diffusion의 입력으로 들어가도록 하여 이미지를 생성하는 방식을 사용한다.

Zhu, Deyao, et al. "Minigpt-4: Enhancing vision-language understanding with advanced large language models." arXiv preprint arXiv:2304.10592 (2023). - Qwen-VL(2023), BLIP2(2023) 또한 동일한 형태를 띄고 있으며, 각각 매핑 네트워크로 Qwen-VL은 cross attention 모듈을, BLIP2는 고정된 길이의 쿼리를 출력하는 Q-former를 사용한다.

Bai, Jinze, et al. "Qwen technical report." arXiv preprint arXiv:2309.16609 (2023). Li, Junnan, et al. "Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models." International conference on machine learning. PMLR, 2023. 3. A Guide to VLM Training
Recipes that are used to create datasets for training VLMs
- 논문에서는 VLM 학습을 위한 데이터셋을 구성하거나 정제하는 것에 관한 방법으로 다음의 여섯가지를 설명하고 있다.
- Heuristics
- Ranking based on Pretrained VLMs (CLIP)
- Diversity and Balancing
- Synthetic data
- Data augmentation
- Interleaved data curation
- 이 중에서, 위의 세 가지 방법은 데이터셋에서 중복을 제거하거나, 정보량이 많은 데이터를 남기고 Noisy한 데이터를 제거하는 방법이며, 그 아래의 두 가지는 합성 데이터 또는 Data augmentation을 활용하여 다양성 있는 데이터셋을 만드는 방법이다.
- 마지막으로 Interleaved data curation은 이미지와 텍스트가 교차한 데이터셋을 구성하여 모델이 멀티모달에 대해 잘 학습할 수 있는 데이터를 구성하는 방법이다.


Interleaved Data Curation Improve Accuracy
- 논문에서는 VLM의 성능을 높일 수 있는 방법으로 Bounding Box (Grounding)와 instruction tuning을 활용하는 부분에 대해 설명하고 있다.
- Grounding은 모델이 이미지의 특정 영역이나 객체를 텍스트와 연결지을 수 있는 능력으로, 본 논문에서는 VLM의 grounding을 향상시킬 수 있는 방법으로 Bounding box를 사용하는 방식은 COCO와 같은 Object detection 데이터셋을 활용하며, 이미지 내 객체에 대한 bounding box annotion을 제공함으로써, 모델이 객체의 위치와 크기를 정확하게 학습하도록 한다.

- 아래의 그림에 나와있는 내용은 Contrastive region guidance 라는 제목의 논문인데, 흥미로운 사실은, VLM을 학습하지 않고도, 단순히 Bounding Box 영역을 모델에 제공한 이미지에 대한 결과와, 그 bounding box를 masking한 결과의 차를 통해 정답값을 구하는것만으로도, ViP Bench 데이터셋에서 11 퍼센트의 성능 향상을 얻을 수 있었다고 한다.

Wan, David, et al. "Contrastive region guidance: Improving grounding in vision-language models without training." arXiv preprint arXiv:2403.02325 (2024) - 다음으로 Instruction Tuning은 다양한 Task를 지시와 그에 대응하는 응답으로 구성하여 학습하는 방법으로, 모델의 출력값을 원하는 출력과 alignment 하는데에 사용되는 학습 방법이다.

- LLaVA는 주로 LLM에서 사용되던 Instruction Tuning을 Visual instruction tuning으로 변환하여 MLLM에 적용한 초기 모델 중 하나로, 15만 개의 합성된 instruction-tuning 데이터셋을 활용하여 fine tuning 하는 방법을 사용했다.
- LLaVA-1.5는 LLaVA 모델을 개선해서, 1d projection layer를 MLP로 변경하고, Academic task를 위한 VQA 데이터셋을 병합하여 학습함으로써 LLaVA의 성능을 개선하였다.
- 또한 2024년에 나온 LLaVA-NEXT 모델은 dynamic high resolution 기법을 도입해서 image resolution을 향상시키고, visual instruction tuning data를 개선함으로써 llava-1.5의 성능을 개선하였다.


Improving Text rich Image Understanding
- Text rich image란, 간단히 말해서, 도큐먼트와 같이, 텍스트가 풍부하게 들어있는 이미지를 의미한다.
- Text Rich Image Understanding을 위한 모델로, 대표적으로 LLaVAR과 Monkey가 있다.
- LLaVAR 모델은 OCR 모듈을 활용해서, LAION 데이터셋에 포함된 42만 개의 text rich 이미지에서 텍스트를 추출한 후에 GPT를 통해 생성한 conversation 으롤 이를 학습하는 방법을 사용했으며, Monkey는 이미지의 입력을 일정한 패치로 나누어 슬라이딩 윈도우 방식을 통해 높은 해상도를 유지하면서도 큰 이미지를 작은 조각으로 나눠 병렬 처리함으로써 모델의 효율성과 성능을 높였다.

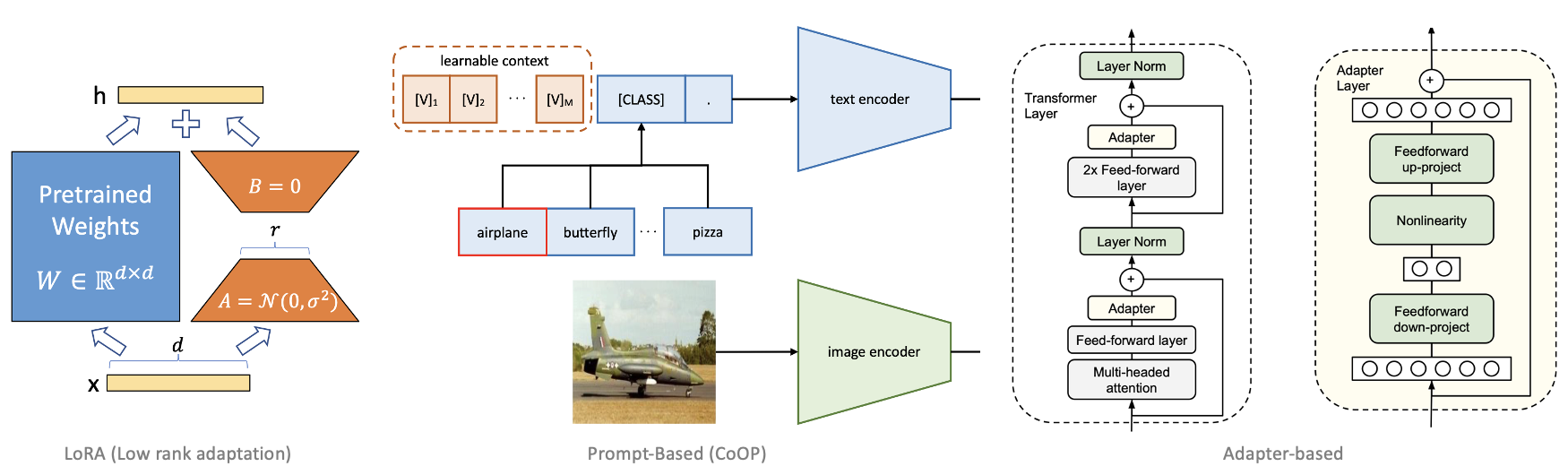
Parameter-efficient fine-tuning (PEFT)
- PEFT 방식으로 대표적으로 LoRA, Prompt based method, Adapter based 기법이 있다.
- LoRA는 Low Rank Adaptation으 약어로 rank decomposition을 통해, 적은 수의 파라미터로 pretrained wieght의 변화량, 델타 W를 학습하는 기법이다.
- Prompt-based method는 VLM에 입력으로 들어가는 prompt를 engineering을 통해 수동으로 만들어내는 대신에, 이 prompt를 learnable vector로써 학습하는 방법을 사용하는 기법이다.
- Adapter based 기법은 pretrained network의 사이사이에 새로운 모듈을 추가하여 학습하는 기법입니다.
- 세 가지 기법 모두, Full Finetuning과 비교했을 때 적은 수의 파라미터만을 튜닝하면서도, 그에 대응하는 성능을 도출하는 기법이며, 이중에서 특히 LoRA는 LLM에서 가장 널리 사용되는 기법 중에 하나이다.
4. Extending VLMs to Videos
Early work on Videos based on BERT
- Video BERT는 비디오, 텍스트 시퀀스를 단순히 concat한 다음 BERT의 입력으로 사용한 모델로, VL-BERT와 유사하게, BERT의 pretraining 기법들을 비디오 멀티모달에 맞춰 변형하여 학습하는 방법을 사용하였다.
- 구체적으로는 주어진 캡션과 영상이 같은 시간에서 뽑혔는지 여부를 binary classificatio으로 학습하는 Temporal Alignment Prediction 기법을 사용하였으며, 비디오 또는 캡션, 그리고 둘다에 마스킹을 적용하여 학습하는 방법을 사용하였다.

Sun, Chen, et al. "Videobert: A joint model for video and language representation learning." Proceedings of the IEEE/CVF international conference on computer vision. 2019. 
Sun, Chen, et al. "Videobert: A joint model for video and language representation learning." Proceedings of the IEEE/CVF international conference on computer vision. 2019. - Video-LLaMA는 BLIP-2 아키텍쳐에 기반하며 Video frame과 audio signal을 분리된 모듈로 처리하고 이를 LLM의 입력으로 사용하는 방식을 사용하였고, MiniGPT-4-Video의 경우, 비디오의 네 개의 이웃하는 프레임을 하나의 토큰으로 사용하여 압축하였으며, 각 프레임의 자막에서 추출한 텍스트 토큰과 visual toekn을 혼합하는 방식을 통해 비디오 내용을 보다 잘 이해할 수 있도록 했다.

Zhang, Hang, Xin Li, and Lidong Bing. "Video-llama: An instruction-tuned audio-visual language model for video understanding." arXiv preprint arXiv:2306.02858 (2023). 
Ataallah, Kirolos, et al. "Minigpt4-video: Advancing multimodal llms for video understanding with interleaved visual-textual tokens." arXiv preprint arXiv:2404.03413 (2024). 참고 문헌
- Su, Weijie, et al. "Vl-bert: Pre-training of generic visual-linguistic representations." arXiv preprint arXiv:1908.08530 (2019).
- Lu, Jiasen, et al. "Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks." Advances in neural information processing systems 32 (2019).
- Radford, Alec, et al. "Learning transferable visual models from natural language supervision." International conference on machine learning. PMLR, 2021.
- Zhai, Xiaohua, et al. "Lavoie, Samuel, et al. "Modeling caption diversity in contrastive vision-language pretraining." arXiv preprint arXiv:2405.00740(2024).
- Sigmoid loss for language image pre-training." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023.
- Yu, Jiahui, et al. "Coca: Contrastive captioners are image-text foundation models." arXiv preprint arXiv:2205.01917 (2022).
- Yu, Lili, et al. "Scaling autoregressive multi-modal models: Pretraining and instruction tuning." arXiv preprint arXiv:2309.02591 2.3 (2023).
- Team, Chameleon. "Chameleon: Mixed-modal early-fusion foundation models." arXiv preprint arXiv:2405.09818 (2024).
- Singh, Amanpreet, et al. "Flava: A foundational language and vision alignment model." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
- Yin, Shukang, et al. "A survey on multimodal large language models." arXiv preprint arXiv:2306.13549 (2023).
- Tsimpoukelli, Maria, et al. "Multimodal few-shot learning with frozen language models." Advances in Neural Information Processing Systems 34 (2021): 200-212.
- Zhu, Deyao, et al. "Minigpt-4: Enhancing vision-language understanding with advanced large language models." arXiv preprint arXiv:2304.10592 (2023).
- Bai, Jinze, et al. "Qwen technical report." arXiv preprint arXiv:2309.16609 (2023).
- Li, Junnan, et al. "Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models." International conference on machine learning. PMLR, 2023.
- Zhou, Hantao, et al. "UniQA: Unified Vision-Language Pre-training for Image Quality and Aesthetic Assessment." arXiv preprint arXiv:2406.01069 (2024).
- Wan, David, et al. "Contrastive region guidance: Improving grounding in vision-language models without training." arXiv preprint arXiv:2403.02325 (2024).
- Liu, Haotian, et al. "Visual instruction tuning." Advances in neural information processing systems 36 (2024).
- Zhang, Yanzhe, et al. "Llavar: Enhanced visual instruction tuning for text-rich image understanding." arXiv preprint arXiv:2306.17107 (2023).
- Li, Zhang, et al. "Monkey: Image resolution and text label are important things for large multi-modal models." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024.
- Sun, Chen, et al. "Videobert: A joint model for video and language representation learning." Proceedings of the IEEE/CVF international conference on computer vision. 2019.
- Zhang, Hang, Xin Li, and Lidong Bing. "Video-llama: An instruction-tuned audio-visual language model for video understanding." arXiv preprint arXiv:2306.02858 (2023).
- Ataallah, Kirolos, et al. "Minigpt4-video: Advancing multimodal llms for video understanding with interleaved visual-textual tokens." arXiv preprint arXiv:2404.03413 (2024).
'Computer Vision' 카테고리의 다른 글